Abstract
BERT처럼 pre-trained 베스로 한 노이즈 없애는 오토인코딩(auto-encoding)은 오토리그레시브(auto-regressive) 언어모델 베이스 방법보다 더 성능이 좋음.
그런데 BERT가 학습 할때 mask에 의존적이자나? 그때 학습한 mask위치 하고 파인튜닝(fine tune)할때 mask 위치 하고 차이가 무조건 있는데 BERT는 그딴거 무시하고 파인튜닝함.
그니깐 기본적으로 오토리그레시브보다 오토인코딩이 성능이 좋은데 mask 위치에 의존적이라 파인튜닝 할때 모순이 발생한다는 단점이 있단말.
이런 장단점을 고려해서 좋은건 넣고 안좋은건 보완해서 XLNet이라는 오토리그레시브 기반 모델 만듬.
문맥을 단어의 모든 순서 조합으로 읽어 likelihood를 최대화하는 방향으로 학습함.
즉, 오토리그레시브의 단점 봉쇄!
그리고 오토리그레시브이기때문에 BERT가 가지고 있는 단점도 없음.
게다가 오토리그레시브의 SOTA모델인 Transformer-XL을 활용해서 XLNet을 만듬.
궁극적으로!!! XLNet이 BERT보다 20개 Task에서 성능 더 좋았음(질문에 답하기, 자연어 추론, 의미 분석, 문서 랭킹 등)
1. Introduction
비지도 표현 학습(Unsupervised representation learning)방법이 자연어 처리분야에서 아주 짭잘함.
특히, 비지도 표현 학습으로 거대한 unlabeld text corpora를 처음으로 신경망에 pre-train 하고 모델 fine-tune하던지 downstram task 하는 등으로 사용됨.
이런 아이디어를 바탕으로 많은 비지도 pretraining 들을 연구했다.
그것들 중에 오토리그레시브(AR) 언어모델하고 오토인코딩(AE) 모델이 자강두천이었음.
AR 언어 모델은 오토리그레시브 모델 가지고 문장 코퍼스(corpus)의 확률을 계산함.
X( ex: 공부 열심히 하자)라는 문장이 주어지면, AR 언어 모델은 주어진 문장의 단어 순서대로(공부 -> 열심히 -> 하자) likelihood를 계산하거나 주어진 문장의 단어를 거꾸로 해서(하자 -> 열심히 -> 공부) likehood 계산함.
그래서 파라미틱 모델(신경망 같은거, 최종 확률 계산해 내는 모델)은 각각의 순서로만 학습을 한다.
그니깐 AR언어 모델은 단방향으로 학습하니깐 순서대로 단어를 줘야 알아먹음. 끽 해봐야 거꾸로 줘야 알아먹는 수듄... 양방향 문맥 이해를 잘 못함.
근데 downstram 언어 이해 task에서는 양방향 문맥 이해가 필요해.
이래서 AR언어 모델 사용해서 pre-train 하면 gap이 생겨버림.
AE모델은 막 확률을 계산하는 건 아니고 input data에 Mask 씌워서 원래 input data가 뭔지 맞추는 식으로 pre-train함.
다들 알만한 걸로 BERT라는 애가 있는데 걔가 pre-train AE모델의 SOTA임.
input tokens 들 중 몇몇개 [MASK]로 바꿔서 주면 원래 token이 뭔지 맞추는 식으로 학습함.
밀도 추정이 목표가 아니기 때문에 BERT는 양방향 문맥을 재구성에서 활용됨.
이러한 장점때문에 AR 언어모델이 앞서말한 AE단점을 해결하고 성능을 향상시켜 대가리가 됨.
근데 pre-train 할 때 사용한 [MASK] 토큰이 실제 데이터를 fine tuning 할때 괴리가 있음.
게다가 마스크된 입력을 예측하기 때문에 BERT는 AR방식의 확률결합 방식을 사용 할 수 없음.
즉, BERT는 MASK token이 마스크 안된 토큰들과는 독립적이다 라고 가정하고 예측하는 것.
이게 자연어 처리의 고질적인 문제인 high-order, long-range 의존성을 너무 간소화 시킨 것.
우리는 앞선 장단점들을 고려해서 일반화된 오토리그레시브 방식인 XLNet을 제안.
AR과 AE 모두를 활용하되 단점들은 피함.
● 첫번째로 AR문제인 고정된 순서로 학습하는 것 대신에 XLNet은 단어의 모든 순서 조합을 고려해서 log likelihood값을 최대화 하는 방향으로 학습.
그니깐 "나는 학교에 가다" 라는 문장을 그냥 AR에서는 "나는 -> 학교 -> 가다", "가다 -> 학교 -> 나는" 순서로만 학습했는데
XLNet에서는
"나는->학교->가다",
"나는->가다->학교",
학교->나는->가다",
"학교->가다->나는",
"가다->나는->학교",
"가다->학교->나는"
모든 순서 조합을 학습.
이러한 방식 덕분에 , 문맥은 좌우 방향 모두 포함 할 수 있음.
기대사항으로, 각 위치는 모든 위치의 문맥 정보 활용을 배울 수 있을 거다. 즉 양방향 문맥 정보 따위의 문제는 해결됨.
● 두번째로, AR언어 모델을 일반화 함으로써 XLNet은 데이터 파괴에 영향을 받지 않는다.
그니깐 BERT처럼 [MASK] 넣어서 데이터를 파괴 시켜서 학습 시키는 놈이랑 달리 XLNet은 AR모델이니깐 데이터 파괴 없이 학습함.
그래서 pre-train과 finetuning 사이의 괴리감을 느낄 수 없음.
동시에 BERT는 독립성을 가정해서 token을 예측했는데, XLNet은 확률 결합 방식으로 예특 가능하니깐 그딴 독립성 따위 가정하지 않음.
게다가 XLNet 걍 혁신적인 pre-train 방식이면서 구조적 디자인을 향상 시킴.
● 최신 AR 언어 모델인 Transformer-XL에 감명받아서 XLNet 도 segment recurrence mechanism하고 relative encoding scheme 넣음.
그거 넣으면 긴문장 관련된 task들 좋아짐.
● 근데 단순하게 Transformer-XL 구조를 모든 순서의 조합을 고려한 언어모델에 적용이 안됨.
왜냐하면 인수분해 순서가 애매하고 목표가 분명하지 않기 때문에 안됨.
그래서 그런 모호함을 없애기 위해서 Transformer-XL 의 파라미터를 재구성하는 방식으로 우리가 해결함.
인상적으로 XLNet이 BERT한테 여러 task에 이김.
GLUE 언어 이해 task, SQuAD와 RACE 같은 reading 이해 task, Yelp 와 IMDB같은 언어 분류 task, 그리고 ClueWeb09-B 문서 랭킹 task 등에서 이김.
Related Work
[32, 12]논문 보고 모든 순서 조합 기반 AR 모델을 만들 생각을 함. 하지만 몇 가지 차이가 있음.
첫번째로, 이전 모델은 순서 없는 귀납적 편향을 모델에 적용해서 밀도 추정을 높이고자 했지만 XLNet은 AR 언어 모델이 양방향 문맥을 배우는 것을 가능하게 하는것을 목표했다.
기술적으로는 XLNet은 다양한 target-aware prediction을 하기위해서 two-stream attention 사용해서 target position을 hidden state로 합쳐버림. 이전 모델은 정확한 target position을 MLP 구조로 부터 받았음.
마지막으로, NADE하고 XLNet 둘다 "순서 없음"을 강조 하는데 이말이 input 문장을 랜덤으로 조합 한다는게 아니라 모델이 다양한 미분 순서를 허용한다는 말.
다른 관련 연구로 [11]이 있다. 얘는 문장 생성에서 오토리그레시브 디노이징을 사용함. 하지만 오직 고정된 순서만 고려함.
2 Proposed Method
2.1 Background
여기선 전통적인 AR 언어모델과 BERT의 언어 pre-traing 방법을 리뷰하고 비교해 볼것이다.
X = [x1, x2, ..., xT] 라는 문장이 주어지면, AR언어 모델은 아래 식을 사용해서 liklihood를 최대화 하는 방식으로 pre-training을 한다.
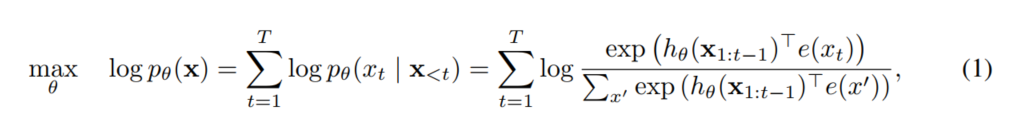
h(x1:t-1) 함수는 RNN이나 Transformer 같은 신경망 모델에서 만든 문장 표현을 의미한다.
e(x)는 x라는 문장을 임베딩한 것을 의미함.
BERT하고 비교해보면 BERT는 디노이징 오토 인코딩 기반이다.
뭔말이냐면 BERT는 먼저 문장을 [MASK] 토큰 사용해서 램덤하게 문장을 파괴해야해.
그렇게 파괴된 문장을 x^ 이라하고 [MASK]토큰을 x_라고하면 BERT의 목적은 x^에 있는 x_를 재구성하는 것을 목표로 학습함.
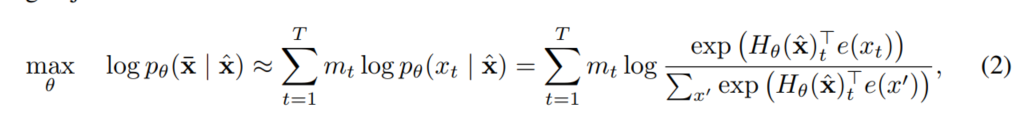
mt=1 이면 xt가 [MASK] 토큰이란 뜻.
Hθ는 Transformer이다.
예로 길이가 T인 문장 x를 입력으로 주면 Hθ(x) = [ Hθ(x)1, Hθ(x)2, ... , Hθ(x)T] 로 나타내줌.
두 pre-training 목표에 장단점이 있음.
● 독립을 가정함.
(2)식 보면 물결 등호를 강조해서 표시 했다.
BERT는 결합 조건부 확률 p(x_|x^)을 인수분해 했는데 이건 독립을 가정해야 할 수 있다.
즉, 랜덤으로 선정된 모든 [MASK]토큰이 서로의 의미에 전혀 영향을 주지 않는다 생각하고 예측(재구성)했다는 것.
반면에 AR 언어 모델의 목표는 p θ(x)를 인수분해 했는데 이건 내적 룰을 따른 거라서 어떠한 독립을 가정하지 않음.
● 노이즈 입력함.
BERT는 원문에 없는 [MASK] 토큰을 문장에 넣음. 그 때문에 fine-tuning과 pre-train 사이 괴리 발생.
[10]논문 처럼 [MASK] 토큰 대신에 original 토큰을 넣는다고 해도 해결 안됨.
왜냐면 original 토큰이 아주 작은 확률을 가지기 때문임.
original 토큰이 아주 작은 확률을 가지지 않으면 (2)식은 최적화하기 엄청 쉬움.
반면에 AR 언어 모델은 입력에 [MASK] 안 넣으니깐 이러한 문제 전혀 없음.
● 문맥 의존성.
AR모델의 문장 표현 h θ(x1:t-1)은 토큰이 무조건 t 위치에 있어야 한다는 조건이 있다.
반면에 BERT의 문장 표현 H θ(x)t 양방향 문맥정보를 가짐.
그 결과 BERT 목표가 양방향 문맥을 잘 이해하면서 pre-trained 됨.
2.2 Objective: Permutation Language Modeling
위에서 BERT랑 AR 언어 모델 비교한거 보면 각각의 장단점이 있음.
그래서 pre-training objective의 단점은 놔두고 장점만 쏙쏙 빼올 수는 없을까?
NADE 모델의 아이디어에서 영감받아서 만든 permutaion(순열) 언어 모델이 단점은 없애고 장점들만 쏙쏙 빼옴.
특히 문장길이가 T이면 T!개의 문장 순서를 만들어서 AR방식의 인수분해를 한다.
만약에 파라미터들의 모든 순서의 인수분해 결과를 공유한다면 모델은 모든 위치에서의 정보를 함쳐서 학습할 것이다.
아이디어를 정형화하자면, 일단 Zt를 가능한 모든 순서의 문장이라고 하자.
Zt 는 t번째 요소를 의미하고 Z<t 는 처음부터 t-1번째 까지 요소를 의미한다.
그러면 우리가 제안한 permutation 언어 모델의 목표는 아래 식으로 표현 가능.

일단 미분 순서 z를 샘플링 하고 순서에 따라서 likelihood p θ(x) 값을 미분함.
학습 중에느 파라미터 θ 값을 모든 미분 순서 z 가 공유하기 때문에 xt가 가능한 모든 요소와의 관계를 고려함.
그렇기 때문에 양방향 문맥적 의미를 이해할 수 있음.
게다가 목표가 AR 언어모델과 같기 때문에 독립 가정과 pre-train 과 fine-tuning 사이 괴리 라는 문제도 해결 할 수 있다.
Remark on Permutation
제안한 목표는 미분 순서의 순열이지 문장의 순서가 아니다!!!
즉, 우리는 원문장의 순서는 건드리지 않는다.
원 문장의 순서와 연관 있는 positional encoddings을 건드리는 거다!!!
Transformers에 있는 적절한 attention mask를 사용해서 순열의 미분 순서를 구한다.
fine-tuning 할때 자연스러운 순서의 문장만 만나기 때문에 이렇게 무조건 해야함.
문장 x 주면 x3 토큰 예측하는 예시 보여줄게.
2.3 Architecture: Two-Stream Self-Attention for Target-Aware Representations
p.s. 열심히 해봤는데 뭐라는지 모르겠다... 고멘

(a)는 Content stream attention임. 기본 self-attention과 동일함.
(b)는 Query stream attention이다. Xzt에 대한 문맥 정보는 안 가지고 있다.
(c)는 전반적인 permutation 언어 모델의 훈련 과정을 보여줌. 여기에 두가지 stream attention이 있다.
permutation 언어 모델 목표가 원하는 프로퍼티들을 가질동안, 순수 Transformer의 파라미터들은 일 안함.
문제가 뭔지 알기 위해서, Softmax 공식 사용해서 다음 토큰의 분포를 p θ(Xzt | Xz<t)로 나타낼 수 있다고 가정.
즉, p θ(Xzt | Xz) = exp(e(x)T hθ (xz<t )) / sigma {exp(e(x' )T hθ (xz<t ))} 이렇게 나타낼 수 있음.
이때 hθ (xz<t ) 는 Transformer 신경망이 만든 hidden 표현을 뜻함.
그래서 hθ (xz<t )는 어떤 위치를 예측하는지에 영향을 받지 않음.
결론적으로 목표 위치 따위 상관 없이 같은 분포를 예측하는데 이게 유용한 표현을 만들지 않음.
이 문제 해결하려면 다음 토큰의 분포가 다시 파라미터화 시키는 걸 제안. 이거 하면 타겟 위치를 알 수 있음.

여기서 gθ(Xz<t, zt) 는 타겟 포지션을 추가한 표현이다.
Two-Stream Self-Attention
타겟 포지션을 추가한 표현이 타겟 예측에 대한 모호성을 없애긴 했는데 gθ(Xz<t, zt) 가 non-trivial 하다는 것을 어떻게 증명 할까?
타겟 포지션 zt에서 표준을 제시하고 Xz<t 문맥에 대한 정보를 가져오기 위해서 zt를 사용함.
... 더 이상 뭐라는지 모르겟어요..ㅜㅜㅜㅜ 다음에 도전할게요ㅜㅜㅜㅜㅜ
'코딩공부 > 논문읽기' 카테고리의 다른 글
| BART:Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (초월 번역) (0) | 2024.03.15 |
|---|
