Abstract
디노이징 오토인코더인데 pre-training된 seq to seq 모델인 BART를 소개할거야.
BART는 일단 무작위 노이즈 넣은 문장을 사용해서 학습함.
그리고 그걸 다시 노이즈 없었던 문장으로 만들기 위해 학습하는 것.
우리 여러개 노이징 방법들 평가함.
정상적인 문장의 단어 순서를 무작위로 섞고 몇개의 단어를 하나의 mask tokens으로 바꿈.
BART는 문장생성에 대해 fine tuning 할때 효과적인데 문장 이해 문제도 잘함.
GLUE와 SQuAD 데이터 셋에서 RoBERTa 와 성능이 동일하고 추상대화와 QA, 요약에서는 SOTA임.
back-translation system for machine translation 분야에서는 BART가 1.1 BLEU증가 시킴.
우리는 절제 실험(ablation experiments)에대한 보고도 했음.
절제 실험은 BART에 다른 pre-training 전략을 복제하는 것임.
그렇게 함으로써 어떤 요소가 end-task 성능에 가장 영향을 주는지 쉽게 측정 가능.
1 Introduction
Self-supervised 방법은 많은 NLP task 좋은 성과를 얻음.
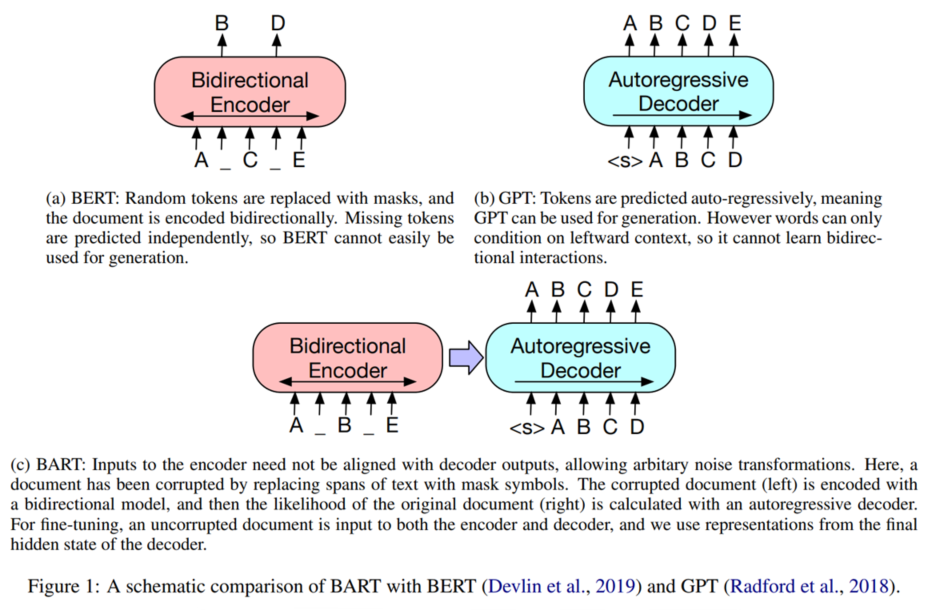
가장 성공적인 방법은 mask 씌운 언어모델임. 기본적으로 디노이징 오토인코더(denoising autoencoders) 구조인데 마스크 전 문장으로 돌리기 위해 학습한 것들임.
최신 연구에서 mask 토큰의 분포를 향상시킴으로써 이득이 많아짐.
하지만 이러한 방식들은 특정 종류의 end tasks에만 집중함으로써 그것들의 활용가능성을 제한.
우리가 제안하는 BART는 Bidrectional 하면서 Auto-Regressive Transformers을 합친 모델임.
BART는 seq-to-seq 모델로 만든 denosing autoencoder이다. 때문에 다양한 end tasks을 할 수 있음.
Pre-training과정은 크게 두 단계 임음.
(1) 무작위 노이즈 함수 사용해서 문장을 망침.
(2) 망쳐 놓은 문장을 seq-to-seq 모델이 원 상태로 돌리도록 학습함.
BART는 기본적인 Transformer-based의 신경 기계 번역 구조를 사용했다.
이 구조은 아주 간단하지만 일반적인 BERT, GPT, 그리고 많은 다른 pre-training 전략 성능과 비견됨.
가장 핵심적인 기능은 노이즈의 유연성(noising flexibility) 이다.
무작위 변환은 문장을 막 바꾸는데 길이 또한 바꿈.
노이징 방법을 여러게 평가했는데 가장 성능이 좋았던건 순서를 무작위로 섞고 0~n 개의 문자를 하나의 mask token으로 바꾸는 식으로 노이즈를 주는 방법이 가장 좋았다.
이 방식이 masking 기법을 일반화 했고 BERT에서 쓴 다음 문장 예측 목표도 일반화 했다.
왜냐면 이런 방식이 모델에게 더 긴 길이의 문장을 추론하게 시켰고 더 긴 영역의 번역을 만들었기 때문입니다.
BART는 문장생성하기 위해서 fine tuning 할때 효과적이다.
하지만 이해 task에서도 일을 잘 함.
RoBERTa 랑 GLUE 하고 SQuAD 데이터로 비교했을때 지지않고 range of abstractive dialogue, QA, summarization task에서는 SOTA를 차지함.
예로들어 6ROUGE에서 이전 결과보다 더 좋은 결과 냄.
BART 도 새로운 방법으로 fine tuning 가능.
machine translation 부분에서 새로운 전략을 제시했는데 그게 BART모델에 추가 transformer layer 쌓는거임.
이 layer들이 외국어를 노이즈된 영어로 바꾸는 방향으로 학습함.
BART를 통해 전파 하는데 이때, 목표하는 pre-trained 언어 모델로써 BART를 사용함.
이러한 방법은 강력한 back-translation MT의 기준치를 WMT Romanian-English benchmark 데이터 셋에서 1.1BLEU를 기록하며 뛰어 넘음.
이 효과를 잘 알기 위해서, 우리는 제거 분석을 보고함.
이 연구는 많은 요소들을 조심스럽게 제어해야했음. 데이터, 최적화 파라미터들 등.
BART는 우리가 고려한 다양한 tasks에서 계속적으로 강력한 성능을 보여줬다.
'코딩공부 > 논문읽기' 카테고리의 다른 글
| GPT가 생성형 데이터를 평가하는 방법 (2) | 2024.11.21 |
|---|---|
| XLNet: Generalized Autoregressive Pretraining for Language Understanding (초월 번역) (2) | 2024.03.13 |

