LoRA 왜 사용하는가?
fine tuning이 뭔진 알아?
fine tuning은 내가 원하는 downstream task를 pretrained model이 잘 하기위해서 진행하는 학습을 말합니다.
fine tuning은 크게 두가지 방법이 있습니다.

full fine tuning은 PEFT에 비해 성능은 살짝 높은 경향이 있습니다.
하지만 모든 파라미터 값을 미세조정 하기에 너무 많은 시간이 걸린다는 치명적인 단점이 있습니다.
반면, PEFT는 적절한 몇 개의 파라미터만 미세조정을 하여 full fine tuning에 비해 성능은 살짝 낮은 경향이 있지만 학습에 필요한 시간을 획기적으로 단축시킨 것에 큰 의미가 있습니다.
이러한 PEFT기법에는 prefix tuning, prompt tuning, LoRA 등이 있습니다.
결론적으로 LoRA는 학습 시간이 오래걸리는 full fine tuning 문제를 해결하고자 사용되는 PEFT 기법 중 하나 입니다.
LoRA는 어떻게 문제를 해결 했는가?

LoRA의 설명들을 보면 "원본 가중치는 고정하고 저차원의 행렬을 추가학습" 한다고들 말하고 있습니다.
이러한 설명이 와닿지 않고, 특히, 논문에도 나온 저 그림을 보고 착가하는 것들이 있습니다.
첫 번째 착각은 Pretrained Weights라고 표시한 파란색 박스가 Pretrained Model의 전체 Weight를 나타낸다고 착각하는 것입니다.
진실은 해당 그림의 Pretrained Weights는 Pretrained Model의 전체 Weight가 아니라 모델의 특정 Layer의 Weight를 의미합니다.
이는 코드를 통해 확실히 알 수 있습니다.
두 번째 착각은 사다리꼴 모양으로 표현한 주황색 저차원 행렬입니다.해당 그림을 보고 저는 AE(Auto Encoder)를 표현 한 것인줄 알았습니다. 진실은 d x r 모양의 직사각 형렬을 사다리 꼴로 모양으로 표현 했습니다. 사다리 꼴 모양으로 표현한 이유는 d 차원으로 입력을 받으면 r 차원으로 output을 반환 한다는 의미를 강조한 그림이라는 것입니다. 해당 부분을 정확하게 그리면 아래와 같습니다.

다시 LoRA에 대해 설명해 보겠습니다.
LoRA는 Pretrained Model의 특정 Layer의 Weight 값을 작은 행렬 두개(A, B)로 분해해서 fine tuning 하는 기법을 의미합니다.
특정 Layer 부분만 두고 봤을 때, full fine tuning의 경우 (d x d) 개의 파라미터를 학습해야한다면 LoRA는 (2 x d x r) 개의 파라미터만 학습하면 됩니다.
참고로 d는 모델마다 값이 다르지만 최신의 모델들은 적어도 512 이상이고, r 값도 설정하기 나름이지만 2 ~ 16 사이로 설정하는 것이 보편적입니다. 심지어 LoRA는 특정 Layer의 파라미터 만을 학습하니 LLM모델들을 fine tuning할 때, 전체 파라미터 수의 약 1% 미만의 파라미터만을 학습한다고 합니다.
구체적인 작동 과정은 코드와 함께 알아봅시다.
코드에서 어떻게 사용해?
LoRA.ipynb
Colab notebook
colab.research.google.com
네이버 영화 리뷰 데이터 셋을 사용해서 "bert-base-case-korean-sentiment" 모델을 학스하는 실습 코드 입니다.
LoRA는 LLM에 적용해야 진가를 보이지만 이해하기 쉽게 하기 위해서 구조가 단순한 bert모델에 적용하는 코드를 가져왔습니다.
자세한 코드 학습은 colab notebook 설명을 참고해주시고 저희는 LoRA를 적용하기 위한 LoraConfig 만을 살펴보겠습니다.

LoRA는 라이브러리가 너무 잘 되어있어 손쉽게 PEFT라이브러리 만으로 구현이 가능합니다.
이때 우리가 설정해줘야하는 부분은 LoraConfig 부분이니 해당 부분에 주요 파라미터 설정을 차례로 알아보겠습니다.
target_modules
target_modules는 pretrained_model의 어떤 Layer에 LoRA를 적용할지 정하는 것입니다.
코드에서 사용하는 모델을 파라미터들만 레어별로 그려보면 아래와 같이 그려집니다.
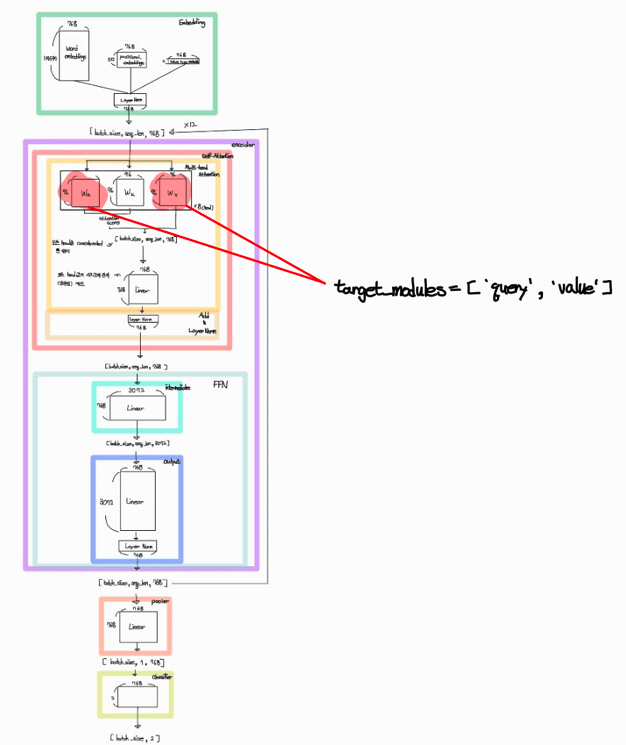
실습코드에서는 target_modules = ['query', 'value'] 로 설정 했기에 빨간색으로 표시한 부분의 Weight 값들만이 학습이 일어납니다.
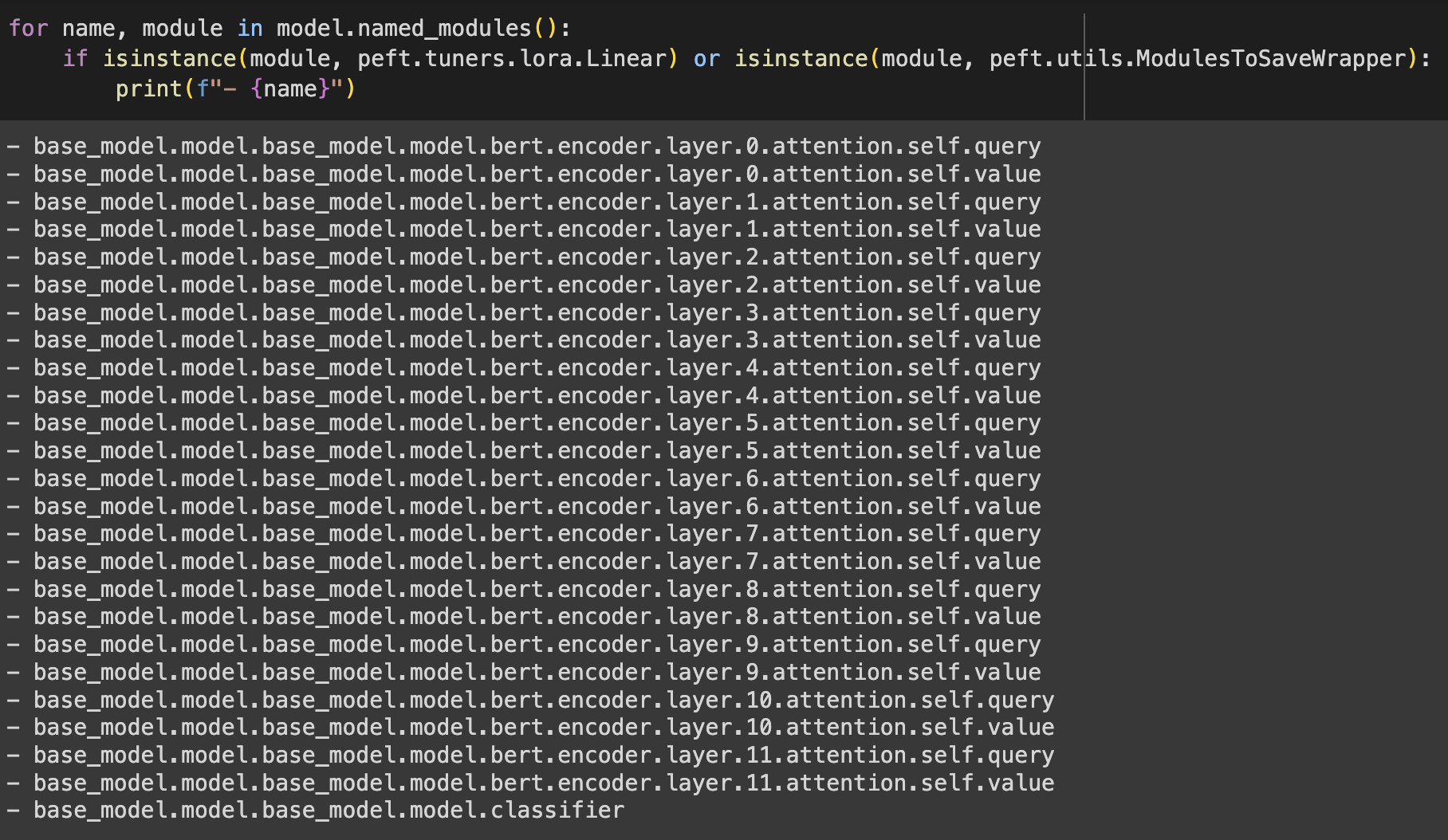
만약 원하는 부분을 더 넣고 싶으면 아래 코드를 통해 layer의 이름을 확인 할 수 있습니다. 원하는 layer의 이름을 target_modules에 추가하면 됩니다.
for name, module in model.named_modules():
print(name)
실습 코드에서 LoRA가 적용된 Layer 이름을 프린트 하도록 했는데 그 결과를 보면 아래와 같습니다.
r
r은 앞서 얘기했던 행렬분해를 몇 차원으로 할지에 대한 파라미터 입니다.
실습 코드에서 사용한 모델과 설정을 기준으로 그림을 그려보면 아래와 같습니다.
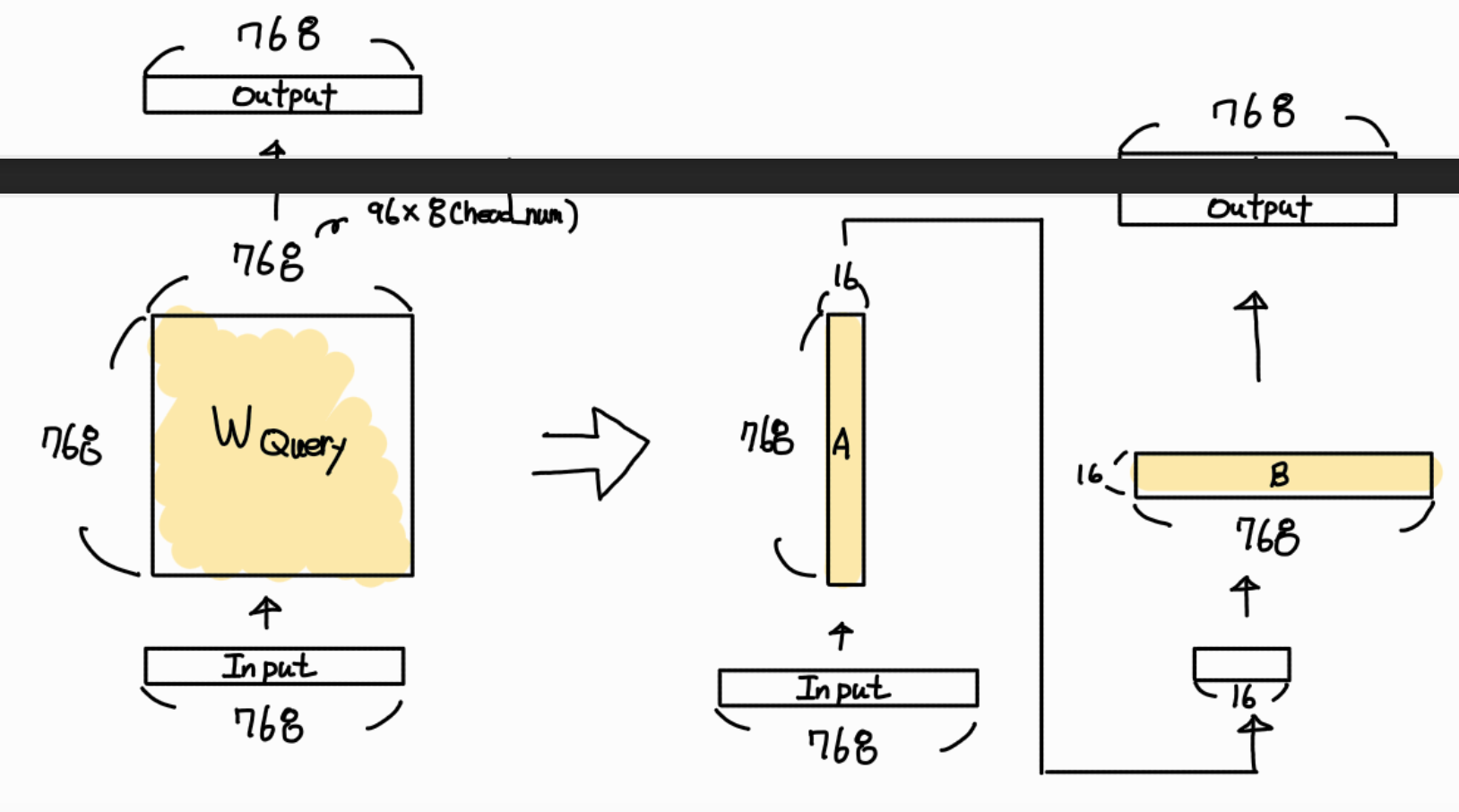
786 x 768개의 파라미터가 2 x 16 x 768개가 되어 학습 되는 모습입니다.
하지만 기존 Weight를 전혀 사용하지 않는 것은 아닙니다.
최종 output을 도출 할때 아래와 같은 수식을 사용하여 도출합니다.
최종 Output = Pretrained Weight Output + LoRA Output제가 느끼기에는 skip connection 처럼 잔차학습의 개념이 아닐까 합니다.이상적인 r값을 지정하기 위해서는 Pretrained Weight행렬의 고유벡터가 몇 개인지, 즉 rank 값을 알아야 합니다.
이를 선형대수를 사용하여 직접 계산해 낼 수도있지만 매우 복잡하고 힘든 계산 과정이 있어서 실험적으로 r 값을 지정하는 방법이 보편적입니다.
lora_alpha
LoRA가 학습하고 나서 Pretrained Weight 값을 update 하는 과정에서 사용되어지는 파라미터 입니다.
update 과정을 차례로 설명해 보겠습니다.
먼저, A x B를 통해 Pretrained Weight 와 같은 shape로 만듭니다.
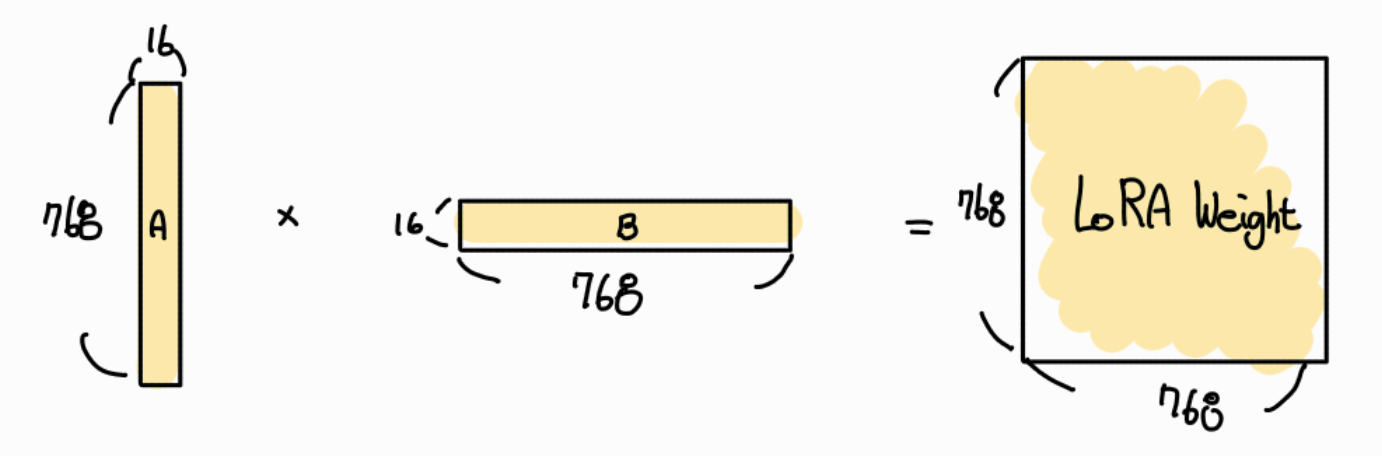
다음으로 Pretrained Weight 값에 LoRA Weight값을 더합니다. 이때 단순히 더하기를 하는 것이아니라 LoRA Weight 에 (lora_alpha / r) 값을 곱한 뒤 더합니다. 즉 스케일링을 한 후 기존 Pretrained Weight 값을 더함으로써 Pretrained Weight 값을 update 합니다.
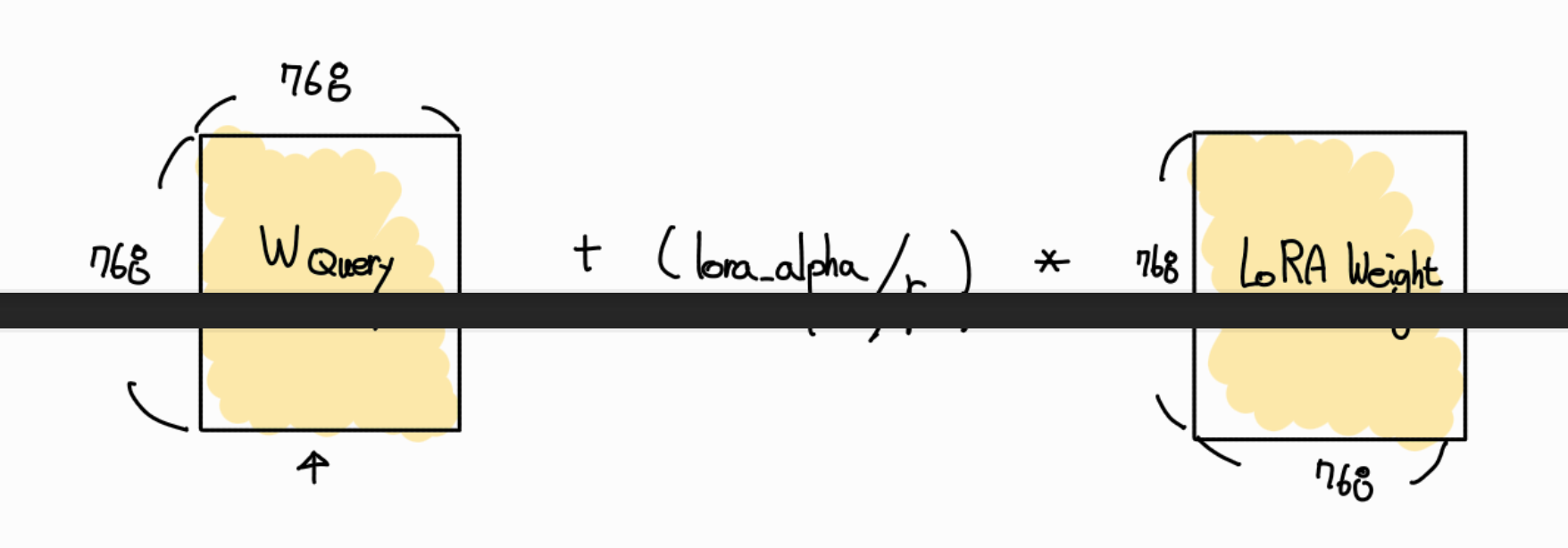
lora alpha 값이 클 수록 새로 학습한 값에 대한 영향이 증가하고, 값이 작을 수록 기존 Pretrained Weight값을 고수하는 것입니다.
r값이 큰 경우, lora_alpha 값은 r값의 1/2 혹은 1/4 정도를 보편적으로 사용합니다.
반대로 r 값이 작은 경우, lora_alpha 값은 r값의 2배 3배 정도를 보편적으로 사용합니다.
이외 다른 drop_out, task_type, bias대한 설명은 생략합니다.
직관적이고 lora작동과정을 이해하는데에는 직접적 영관이 있는 파라미터들은 아니라 생략했으니 관심 가시는 분들은 더 찾아보시는 것을 추천드립니다.
글을 마무리 하면서
LoRA에서 진화된 QLoRA, QA-LoRA등 이 있습니다. 해당 부분도 찾아서 공부하시면 재미날 것 같습니다.
LoRA는 LLM이 발전해 오면서 많은 곳에서 사용되는 기술이니 이번 기회에 정확히 이해하시길 바라면서 논문 링크 남기면서 글을 마칩니다.
https://arxiv.org/pdf/2106.09685
'코딩공부 > 패스트캠퍼스 AI 부트캠프' 카테고리의 다른 글
| [Fastcampus Upstage AI Lab] 대화문 요약 대회 후기 (0) | 2024.09.17 |
|---|---|
| Computer Vision 모델 발전 과정 (1) | 2024.08.21 |
| 문서 이미지 타입 분류 대회 후기 ( FastCampus Upstage AI LAB) (0) | 2024.08.19 |
| House price predict 경진대회 후기 (0) | 2024.07.25 |
| Machine Learning 모델 종류 정리 (0) | 2024.07.15 |



