
24년 7월 31 ~ 8월 11일(2주) 진행되었던 Image classification 대회가 막을 내렸다.
인강을 수강하면서 진행 해야 했기에 시간적인 부분에서도 많은 압박을 받았지만 나름 재밌게 대회를 진행해서 좋았다.
특히 좋은 팀원들과 함께 하여서 많은 의견도 적극적으로 나누고 협업도 하면서 진행하여 좋았다.

비록 8위로 끝나서 아쉬움이 있긴 하지만 솔찍히 4위 까지는 스치면 엎어지는 점수들이라 우리는 마음만큼은 4위 였다.
1~3위는 확실히 방법적인 면에서 많은 것들을 배울 수 있어서 추후 해당 방법들을 직접 해봐야 겠다고 생각했다.
혹시 이 글을 읽게될 Upastage AI LAB 3기 이후 기수들에게 말씀드리자면 3 - 7 클래스를 구별해내는 기발한 시도들이 3기에 이루어졌고 그것을 정리해 놓을테니 꼭 참고하셔서 시도해 보세요!!!
대회 소개
이미지 데이터가 주어지면 해당 이미지가 어떤 클래스에 해당하는 이미지인지 판단하는 모델을 만드는 대회 였다.

실제 데이터를 받아보면 위 사진과 같이 문서에 대한 이미지들과 자동차 번호판에 대한 이미지 등 총 17가지 종류의 데이터가 있다.
해당 데이터들을 학습을 잘해서 특정 이미지를 입력으로 받으면 어떤 종류의 이미지인지 판단하는 모델을 만드는 것이 이번 대회의 목표이다.
EDA
1. 이미지 해상도
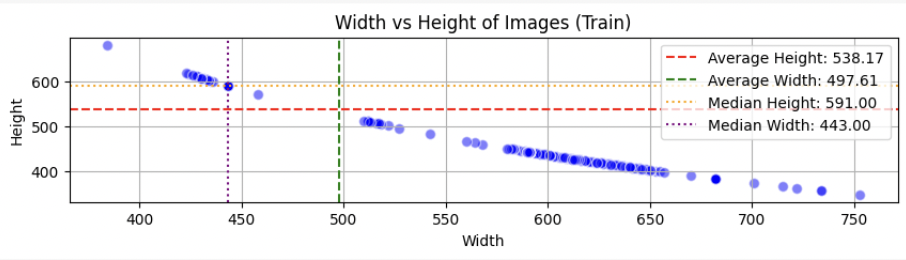
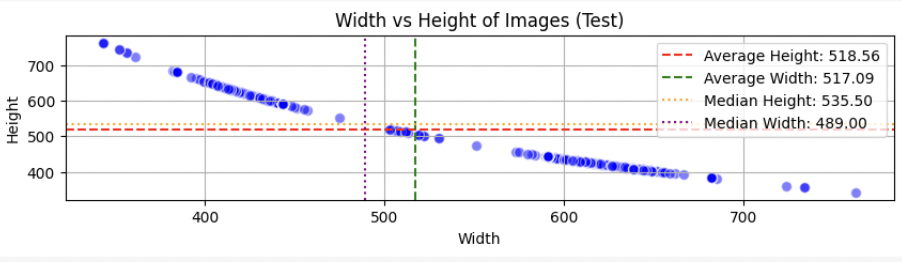
이미지 해상도의 분포를 보면 Full HD급(1920 x 1080) 보다도, 훨씬 작은 SD급(640 x 480) 정도의 사이즈로 확인된다.
resize 할때 참고하여 최대한 정보 손실 없으면서도 학습에 적절한 사이즈를 찾는 것이 중요하다.
우리는 해당 EDA를 바탕으로 380 x 380 크기로 리사이즈 했다.
2. 클래스 별 데이터 수

클래스별 train데이터 수를 보면 불균형은 분명히 있었다.
이를 해결하고자 데이터 샘플링을 하거나 증강을 해야 했는데 우리팀은 데이터 증강을 선택했다.
이 대회를 참여한 사람이라면 알고 있겠지만 train 데이터와 test 데이터의 차이가 너무 크다.

실제로 train dataset은 깔끔하게 이미지가 있는 반면 test dataset에는 flip, rotate, mixup, shift, noise 등 많은 기법들을 사용해서 최대한 데이터를 오염시키고자 노력한 것으로 보인다.
3. 잘못된 라벨링

train data를 하나씩 뜯어보면 라벨링이 잘못된 데이터가 있다.
우리팀도 데이터 이해를 하기위해서 하나씩 이미지를 직접보고 라벨링 된것을 확인하면서 해당 데이터들을 찾아냈고 해당데이터들은 올바른 라벨링으로 바꿔 주었다.
validation set 구축

validation set을 구축 할때 중요하게 생각하는 것은 test 데이터와 유사한 데이터들이어야 하고 train data를 최대한 확보 할 수 있게 하면서도 편향이 일어나지 않을 정도의 데이터를 validation set으로 구축해야한다.
그래서 우리는 test dataset을 샘플링 해서 validation set으로 구축하기로 결정했다.(이보다 더 test data 와 유사할 수 없으며 train data 의 학습량에도 영향을 주지 않을 수 있는 방법이 있을까?)
test dataset을 하나씩 확인하면서 노이즈가 심한 51개를 추출.
랜덤하게 250개 데이터를 샘플링.
두가지 데이터를 합친 301개의 데이터를 이미지를 확인하며 직접 레이블링 진행 했다.
그중 29개는 노이즈가 너무 심해서 사람이 판단하기도 힘든 데이터라 drop 하고 1번, 14번 클래스에 해당하는 데이터의 수가 너무 적어서 각각 12개씩 train data에 샘플링하여 노이즈를 추가한 후 validation set에 추가했다.
실제로 validation set과 leader board 점수 차이는 적었기에(+- 0.05) 신뢰가능한 validation set을 구축했다고 평가했다.
다른 팀들은 보통 hold out 방법으로 validation set을 만들었고 2등을 한 팀은 validation set 을 일부러 구축하지 않았다고 했다.
validation set을 구축하지 않은 이유로는 train 과 test 데이터 셋을 봤을 때 OOD 데이터 셋이 없다고 판단했다고 한다.
또한 train dataset에 과적합 할 수록 leader boad 상에서 점수가 올라가는 것을 확인하고 확신 했다고 합니다.
Model Selection

모델을 선택하기 위해 우리가 배운 모델들을 후보로 두고 실제로 실험을 해보았다.
데이터는 flip을 이용해서 데이터 증강을 한 12560개의 train data를 가지고 간단하게 실험하였다.
그래프를 보면 transformer 기반의 모델들이 바닥을 기는 것을 알 수 있다.
따라서 우리는 efficientnet_b4를 base를 두고 실행 했고 그 외에도 resnet50, efficientnet_b0를 추가적으로 사용했다.
추후에 더 많은 데이터 증강 기법을 사용해서 데이터가 20만장 까지 늘어나는데 이때 모델 실험을 다시 진행했다.
왜냐하면 간단하고 정보량이 적은 데이터때문에 transformer 기반의 모델들이 성능이 안나왔을 것이다 라고 가정을 두고 실험을 진행했다.
실험 결과 transformer 기반의 모델들이 0.9 가까이 성능이 커졌다. 하지만 여전히 CNN기반의 모델들에 비해 성능이 낮아 해당 모델들은 배제하고 사용했다.
다른 팀들을 보면 똑똑하게 서버의 자원 까지 고려해서 ViT 모델을 선택한 팀도 있었고 대부분은 efficientnet_b4를 사용한 것 같다.
하지만 자원까지 고려해서 모델 선택하는 인사이트는 진짜 섹시했다. (다음에는 나도 꼭!!)
Augmentation
1. Rotae & Flip & Shift

기본적으로 test 데이터 셋에는 Rotate, Flip, Mixup, Shift, Noise 들이 사용되어서 데이터가 오염되어 있었습니다.
특히 거의 모든 데이터들이 rotate 되어 있었고 상단 수가 flip이 적용되어 있었습니다.
그래서 train 데이터도 30도 단위로 rotate 하고 flip또한 추가해 주었습니다.
대부분의 조는 확률적으로 Augmentation을 사용했지만 저희 팀은 100% 로 적용하여 flip이 된 데이터 안된 데이터 모두 학습하도록 했습니다. 데이터 수가 많아 학습이 오래 걸린다는 단점이 있지만 확실히 모든 데이터를 학습 할 수 있다는 이점을 놓칠 수 없었습니다. 그리고 CNN 기반의 모델을 선택 했기 때문에 학습이 그렇게 오래걸리지 않았습니다.
2. Noise

가장 간단하게 넣을 수 있는 노이즈는 Gaussian 노이즈 일 것입니다. 하지만 정성적으로 평가 했을때 Test 데이터 셋에 들어가 있는 노이즈와 Gaussian이 적용된 노이즈를 비교했을 때 너무 다른 노이즈임을 알 수 있습니다.
그래서 여러 노이즈를 찾아 보던 중 Augraphy에 있는 Voronoi noise가 test 데이터 셋에 적용되어 있는 노이즈와 유사함을 알 수 있었습니다. 하지만 비교실험을 한 결과 voronoi를 적용한 데이터 셋이 gaussian을 적용한 데이터 셋 보다 약 0.06이나 떨어지는 성능을 보여주어서 해당 노이즈를 폐기했었습니다.
하지만 멘토님이 피드백 해주실 때마다 Augraphy를 더 적절히 사용했으면 좋은 성능이 나왔을 것이라는 피드백을 많이 주셨는데 이를 통해 Test dataset은 Augraphy의 여러 기법들을 사용해서 데이터를 오염 시켰음을 유추 할 수 있었습니다.
3. Patch

두 이미지를 섞는 Mixup 방식인 Patch를 사용해서 데이터 증강을 해보았다.
이부분은 팀원이 맡아서 했는데 test데이터에서 몇몇개가 patch 되어있는 데이터가 있긴 했지만 위 사진처럼 32 x32 사이즈로 조그마하게 패치 된 것은 아니라서 저렇게 조그마하게 붙여넣는다고 성능 향상이 있을까 의문이 많았다.

하지만 결과를 보면 0.9311로 약 0.03이나 성능을 올릴 수 있는 방법이었다.
예상하건데 데이터의 다양성이 늘어서 모델이 강건해 져서 성능이 올라간게 아닌가 싶다.
정확히 왜 성능이 올랐는지 파악하기 위해서는 어떤 데이터들이 성능이 올랐는지 데이터 단위로 확인을 했어야했는데 왜 그걸 생각 못했을까...
아무리 귀찮더라도 데이터 단위로, 이미지 하나하나 확인하자!
4. blending

두 이미지를 섞지만 은은하게 투명도를 주어서 겹치는 것을 blending이라고 한다. 다른 말로는 Mixup 이라고 하고 일반적으로 Mixup이라는 용어를 더 많이 사용한다.
test dataset을 찾아보면 해당 방법으로 데이터 오염이 되어 있는 것들이 많이 있다. 그래서 해당 방법도 기대를 하고 실험을 진행 하였다.

아쉽게도 patch까지 적용한 base model이 약 0.02 정도 성능이 더 높게 나왔다.
따라서 blending기법을 사용한 데이터 증강 방법도 폐기하게 되었다.
BASE MODEL 성능 평가 및 분석

모델은 efficientnet_b4를 사용하고 실험적으로 성능이 향상된 Flip, Rotate, Shift, Gaussian Noise, Patch를 적용해서 데이터 증강 하여 총 116180개 데이터를 학습 시켰다. 이를 통해 리더보드 점수상 0.9311을 얻게 되었다.
Grad CAM

grad-CAM을 통해서 모델이 이미지의 어떤 부분을 집중적으로 보는지 확인해 보았다.
틀린 데이터들을 보면 매우 흐릿하여 feature를 잘 뽑아내지 못하고 있는 모습이 관찰 되었으며, 개인정보 때문에 박스로 가려놓은 부분을 보고 있는 데이터들도 많이 있었음을 확인 할 수 있었다.
90% 이상으로 확신을 가지고 예측하고 정답을 맞춘 이미지들을 보면 전반적으로 해당 이미지의 feature를 잘 파악하고 있음을 알 수 있었다.
Class 별 F1 score

모든 조들이 해결하고자 했던 문제이다. 바로 3, 7, 4, 14 클래스의 성능이 다른 클래스에 비해 떨어진다는 점이다.
특히, 모델이 3 - 7 클래스를 구별하지 못하는 점이 두들어지게 나타났다.
오른쪽 아래 heatmap은 모델이 첫 번째 확신하는 클래스와 두 번째로 확신하는 클래스 사이의 차이가 0.3 이하인 데이터를 모아서 첫번째 클래스와 두번째 클래스의 쌍의 분포를 나타낸 것이다.
예시로 모델이 어떤 이미지의 클래스를 예측할 때, 0.6확률로 7번 클래스라 예상하고 0.35 확률로 3번 클래스 라고 예상한다고 하자.
두 클래스의 확신(확률)차이가 0.25밖에 나지 않으므로 모델이 헷갈려 하고 있다고 할 수있다.
이러한 데이터들을 모아서 만든 heatmap이 바로 오른쪽 아래 사진이다.
heatmap에서도 3 - 7쌍을 헷갈려 하고 있음이 두들어 지고 실제 이미지를 보았을 때도 문서 제목을 읽지 않는 이상 레이아웃이 너무 비슷하여 구분 하기 어렵다고 느껴진다.
Model Enhancement
1. Crop

이미지가 원하는 곳(특히 제목)을 보게 하고 싶고, Resize에 의한 해상도가 파괴되는 문제를 해결하기 위해서 Crop을 사용해 보았다.
224 x 224 사이즈로 Crop을 하는데 제목이 있을 법한 4변의 중심과 정중앙을 중심으로 두고 Crop을 진행했다.
따라서 데이터 수는 5배가 증가 하게 되었다.

결과는 성능이 확 낮아지는 결과를 얻게 되었다. 아마도 의미 없는 부분들이 Crop 되어 성능 저하를 일으켰다고 예상된다.
2. Title Crop

Crop이 이상한 곳을 많이 해서 성능을 많이 떨어진 것 같아 제목만 있는 곳을 Crop 하여 데이터를 증강해 보았다.

이 방법도 아쉽게 성능이 오르진 못 했다. 해당 실험이 대회 마지막 날에 진행 하여 시간에 쫓기며 하여 깜빡하고 padding을 넣는 것을 잊어버렸다. 이미지를 보면 Title Crop 한 데이터들은 가로로 긴 이미지들이 많다. 해당 이미지를 다른 문서 이미지와 같은 방식으로 Resize를 하기 때문에 해상도가 심하게 깨졌을 것이다. 이때문에 성능이 떨어졌다고 예상한다. 만약 시간이 더 있어서 padding을 할 수 있었다면 해당 방식은 좋은 성능을 보였지 않을까 조심스럽게 예상해 본다.
3. Padding


우리가 모델에 넣기 전에 Resize() 함수를 통해 모든 이미지의 크기를 맞추는 과정이 있다.
이 과정 때문에 이미지의 해상도가 깨진다. 특히 많은 문서 이미지들이 직사각형 모양인데 Resize를 하는 순간 이미지가 찌부가 되어버린다.
해당 문제를 해결하기 위해서 이미지 양옆에 흰색 바탕의 padding을 추가 하였다. 이를 통해 Resize를 하더라도 이미지의 해상도가 망가지지 않을 수 있었다.

그러나 예상과 다르게 padding을 적용한 모델이 무려 약 0.1씩이나 성능이 떨어지는 결과를 얻었다.
이해 할 수가 없는 결과이다. 분명 더 좋아져야할 것들 밖에 없었는데...
4. Semi Supervised Learning

많은 데이터 증강 방법을 사용했지만 train 의 데이터 분포와 test의 데이터 분포가 많이 다른지 성능을 향상시키기에 많은 어려움이 있었다.
또한 3 - 7 데이터를 구분하기 위해 많은 시도들을 했지만 해당 데이터의 결정 경계를 확실히 하기에도 많은 어려움이 있었다.
조금 양아치 같은 방법인 것 같지만 확실히 test dataset과 데이터 분포를 같게할 수 있는 방법인 Semi Supervised Learning 방법을 사용해 보았다.
우리의 best model이 0.99이상의 확신을 가지고 예측한 test 데이터들만 모아서 모델이 예측한 클래스로 Pseudo labeling을 달아주는 것이다. 그래서 해당 데이터 셋만을 사용해서 학습을 진행하거나 3, 7 데이터만을 추출하여 기존 train dataset에추가하여 학습하는 방식으로 진행해 보았다.

두 방식 모두 기존 base model에 비해 성능이 떨어졌으며 3-7 데이터를 추가한 방식은 성능은 떨어져도 3 - 7 만은 구분을 더 잘해줬으면 했는데 여전히 구분을 잘 하지 못 하고 있어 많은 아쉬움이 남은 실험이었다.
5. Contrastive Learning

대조 학습이라 불리는 해당 방법은 3 - 7을 구분하고자 하는 우리팀의 발악이었다.
먼저 데이터 쌍을 준비한다. 3 -3, 3- 7, 7 - 7 로 구성된 데이터 셋을 준비하고 같은 클래스면 1을 다른 클래스면 0을 target 값으로 준다. 그리고 이미지 쌍을 모델에 넣어 feature map을 구해내고 두 feature map의 Distance를 계산한다.
Distance가 m보다 멀면 둘은 다른 클래스 인것이고 m보다 가까우면 같은 클래스라고 판별하는 것이다.
실제로 어떤 데이터를 판별 할때는 3, 7의 대표 10개의 데이터 샘플과의 distance를 구해서 평균값을 계산하여 가까운 곳이 어떤 데이터의 클래스라고 판단했다.
그 결과 f1 score는 0.6315, Acc는 0.5625가 나와서 처참했다.
6. OCR


3 - 7 을 구분하기 위해 많은 조들이 시도 한 방법이다. 바로 글을 읽어서 판별하는 OCR 방식이다. 결론부터 말하면 우리팀과 다른 많은 팀들이 실패 했다. 위 이미지에서도 알 수 있듯이 test data가 많이 오염되어 있어서 제대로된 글을 읽히지가 않는다.
하지만 OCR을 통해 성능향상에 성공한 팀도 있었다. 이상하게 읽힌 단어 집합들을 모아서 단어사전을 만들어 Rule base로 판별하였다.
실제로 해본다면 이게 그렇게 간단하지 않다는 것임을 알 수 있을것이다.
일단 OCR 모델을 선택해야 할 것인데 다들 pytesseract, easyOCR을 사용했고 우리도 사용해 보았지만 성능이 좋진 못했다.
성능을 높이기 위해 많은 Denoising 방법을 사용하려고 노력해 보았지만 다들 실패하고 말았다.
우리팀은 멘토님에게 추천 받은 Paddle OCR도 시도해 보았지만 성능은 아쉬웠다.
7. TTA

TTA는 무조건 사용해야한다.
조금 똑똑한 팀은 Flip을 데이터 증강에 넣지 않고 TTA할때 사용하였다. 따라서 데이터 수를 작게 가져가면서도 더 분명한 feature에 관한 값들만 모델이 배울 수 있어 성능을 올렸다는 점이다.
우리도 TTA를 통해 성능을 올리긴 했지만 해당 방법대로 Flip을 데이터 증강에 사용하지말고 TTA 때 적용해서 했으면 좋지 않았을까 생각한다.
8. Ensemble


앙상블도 무조건 적용해야한다.
우리는 하드 보팅과 소프트 보팅 모두 적용해서 비교해 보았는데 역시 소프트 보팅이 확실히 효과가 더 좋았다.
특히 어떤 모델 조합이 가장 좋은지 찾기위해 많은 실험을 했고 이 또한 마지막 발악으로 진행했다. 덕분에 약0.01정도의 성능 향상이 있긴 했다.
회고
다른 팀과 비교해보면 그렇게 많이 다르지 않았지만 정리해보자면 다음과 같은 것들이 있었다.
- Model Selection에 컴퓨팅 자원을 고려하였는가
- Augmentation에 다른 기법들을 섞어가며 확률적으로 적용했는가
- Offline 방식말고 Online 방식을 사용하여 데이터의 다양성을 확보하였는가
- Label Smoothing을 사용하여 3 - 7에 대한 분류 성능을 올렸는가
- cosine annealing warm restarts을 사용하여 location minimum에 빠지지 않으려고 했는가
- Focal Loss를 사용하여 3 - 7 에 대한 결정 경계를 분명히 하고자 노력하였는가
- Wandb Sweep을 사용하여 하이퍼파라미터를 조정 하였는가
이러한 점들이 우리팀이 부족했던 점이었던 것 같다.
너무 데이터 centric에 집중하여 Model centric 부분들을 많이 놓쳤다.
그래도 이번 대회를 통해 많은 실험들을 하고 많은 점들을 배울 수 있어서 좋았다!
'코딩공부 > 패스트캠퍼스 AI 부트캠프' 카테고리의 다른 글
| [Fastcampus Upstage AI Lab] 대화문 요약 대회 후기 (0) | 2024.09.17 |
|---|---|
| Computer Vision 모델 발전 과정 (1) | 2024.08.21 |
| House price predict 경진대회 후기 (0) | 2024.07.25 |
| Machine Learning 모델 종류 정리 (0) | 2024.07.15 |
| MNIST데이터 RNN, LSTM, GRU로 분류기 만들기(pytorch lightning) (0) | 2024.07.01 |



