
seaborn은 데이터 시각화에 있어 많이 사용되는 라이브러리 이다.
matplotlib와 함께 많이 사용되며 seaborn 자체도 matplotlib를 기반으로 만들어 졌다.
seaborn에는 다양한 종류의 그래프가 있는데 각 그래프의 사용법을 알아보자.
1. 그래프 종류
1. 막대 그래프
: histplot, displot, barplot, countplot
2. 선 그래프
: lineplot
3. IQR그래프(박스 그래프)
:boxplot
4. 점 그래프
:scatterplot, pointplot, pairplot
5. 히트맵
:heatmap
선 그래프를 histplot,displot 등 다른 plot을 이용해서 그리지 못하는 것은 아니다.(kde 속성을 사용하면 막대 그래프 그리는 함수로도 그릴 수 있음.) 그러나 주로 사용되는 용도를 기준으로 분류를 해보았다.
다음 그래프를 차례로 그려보면서 알아보자!!
실습을 위해 사용되는 데이터는 seaborn 라이브러리에 내제되어있는 "penguins" 데이터를 사용하자!
import seaborn as sns
from seaborn import load_data
data = load_data('penguins').dropna()
data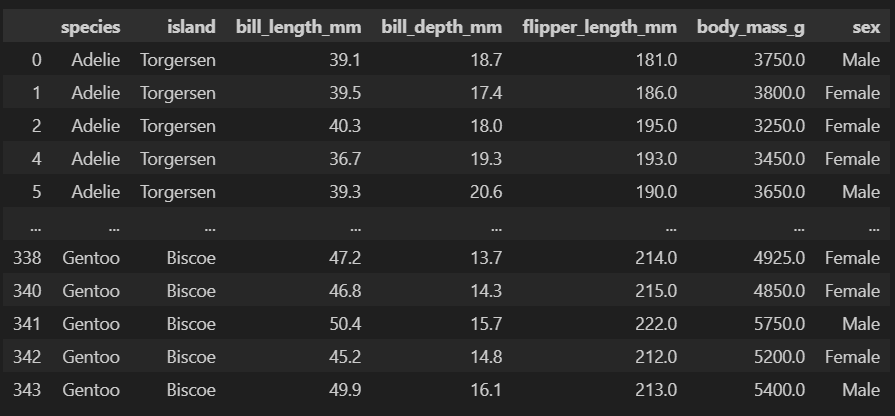
2. 막대그래프 : histplot, displot, countplot, barplot
막대 그래프는 여러 종류가 있다. 이 종류의 가장 큰 차이는 x축과 y축에 표현될 데이터의 종류에 있다.
이를 이해하기 위해서 "범주형 데이터"와 "수치형 데이터"에 대해 이해 할 필요가 있다.
범주형 데이터는 데이터를 특정 집단으로 나누는 데이터를 의미한다. 예로 성별이 있다.
성별은 여 또는 남 으로 구분 가능하다. 즉 데이터를 특정 집단으로 구분 시킬 수 있다.
수치형 데이터는 수치로 나타내는 데이터를 의미한다. 예로들면 키가 있다.
키는 171.2cm 와 같이 수치가 있지 특정 집단으로 나누지는 않는다.
물론 이러한 설명이 정확한 것은아니다.
수치형 안에서도 이산형, 연속형이 있으면 범주형 안에서도 명목형과 순서형이 있다.
이에대한 자세한 설명을 원하는 사람은 데이터의 종류에 대해 공부해보자.
지금은 seaborn을 사용하기 위해서는 저 정도 이해로 충분하다.
| x축 | y축 | |
| histplot | 수치형 데이터 | 해당 범주에 해당하는 데이터 개수 |
| displot | ||
| countplot | 범주형 데이터 | |
| barplot | 수치형 데이터의 대표값 |
크게 정리하면 이렇게 나타낼 수 있다.
(실제로 x축에 수치형 데이터를 넣어야하는데 범주형 데이터를 넣는다고 해서, 혹은 그 반대라고 해서 에러가 발생하는 것은 아니지만 그래프를 사용하는 의도와는 다른 결과를 볼 것이다.)
무슨 말인지 모르겠으니 하나씩 코드와 함께 자세히 보자.
2-1 histplot
import matplotlib.pyplot as plt
plt.figure(figsize=(16,4))
plt.title("Bill Length", fontsize=16, loc='left')
sns.histplot(data=data,
x='bill_length_mm',
bins=15,
hue='species',
multiple='stack',
palette='Spectral',
kde=True)
plt.show()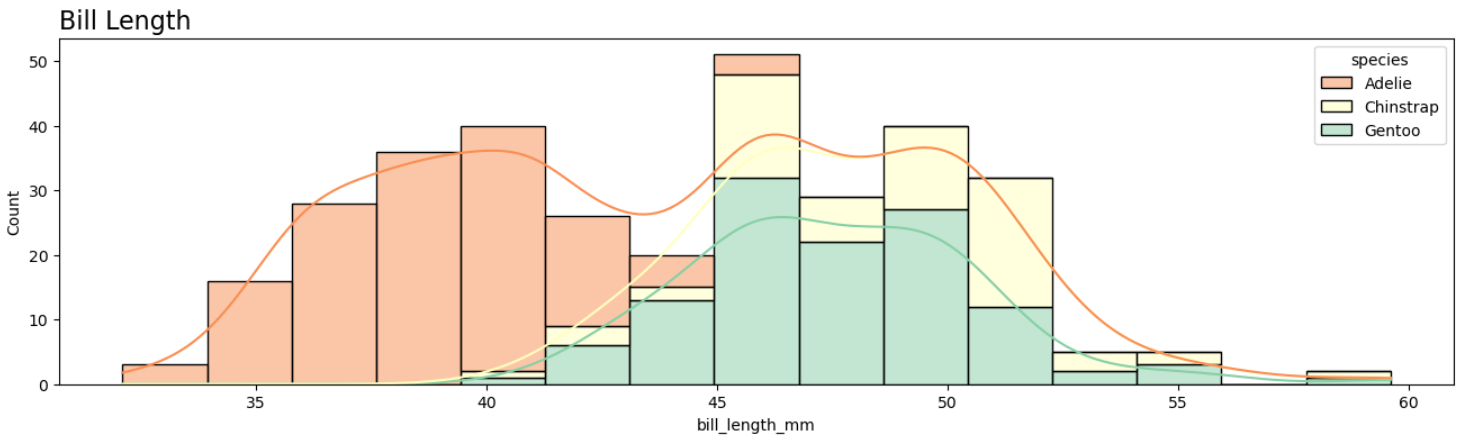
histplot은 다음과 같은 막대 그래프를 그릴 수 있다. (물론 선 그래프도 보이지만 해당 선그래프는 kde=True 속성에 의한 것이다.)
이 그래프는 키, 몸무게, 길이 와 같은 수치형 데이터가 데이터셋의 어떻게 분포되어있는지 알아보고자 할때 사용하는 그래프 이다.
x 속성에 알아보고자하는 수치형 데이터 feature 이름을 입력해주면 해당 feature의 분포를 보여준다.
2-2 displot
sns.displot(data=data,
x="flipper_length_mm",
kind='hist',
col='island',
row='sex',
hue='species',
multiple='stack')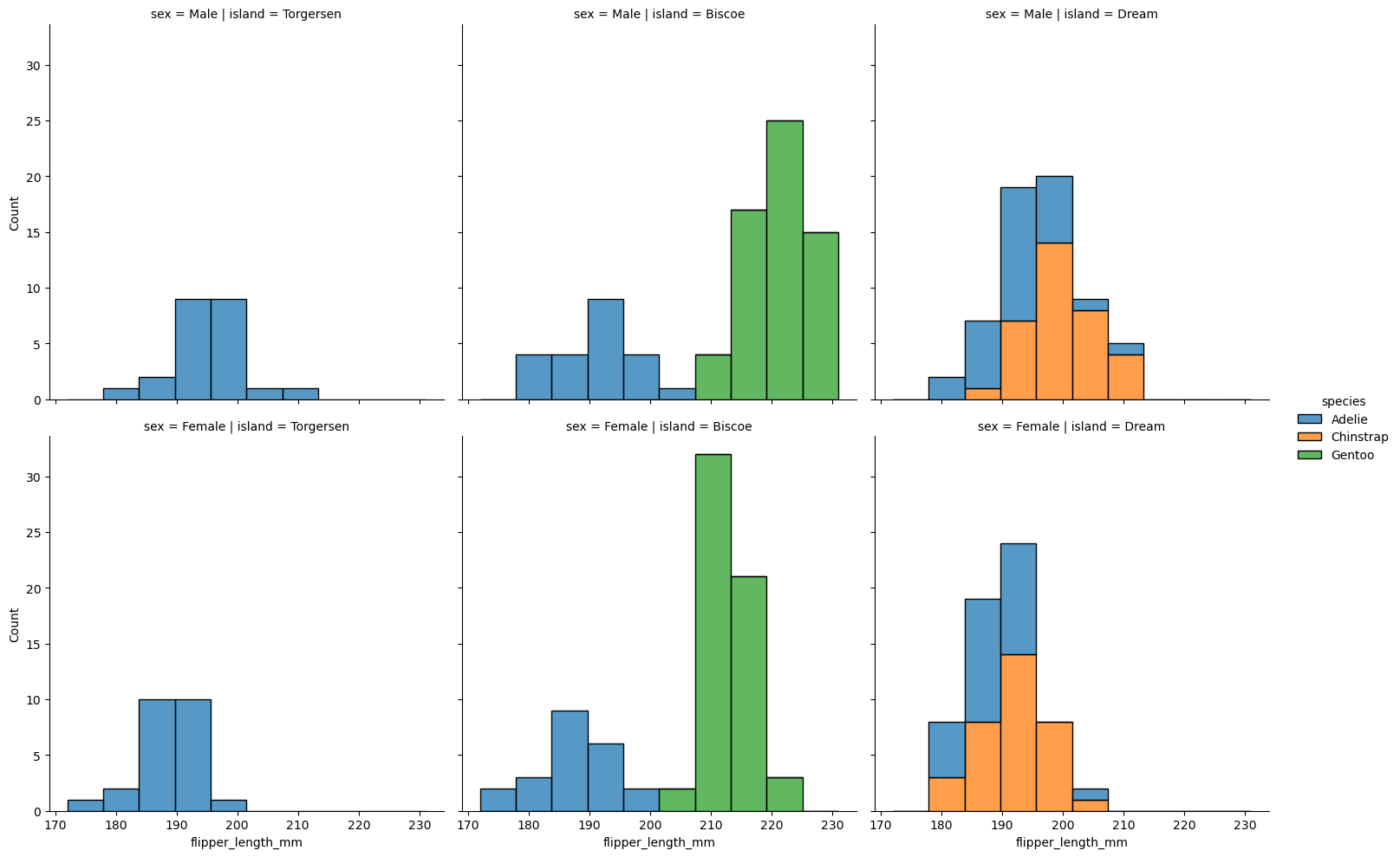
displot그래프는 특정 범주(집단 소속)에 따라 수치형 데이터 분포가 어떻게 다른지 비교해서 보고 싶을때 사용하는 것이다.
모든 데이터가 아닌
남자면서 torgersen 종에 해당하는 펭귄의 날개 길이(filpper_length) 분포와
여자면서 torgersen 종에 해당하는 펭귄의 날개 길이(filpper_length) 분포를 비교해서 보고 싶을 수 있다.
또 각 종별로 날개 갤이 분포가 어떤지 비교해서 보고 싶을 수 있다.(없어도 그렇다고 상상해 보자)
이때 histplot을 사용한다면 원하는 데이터만 추출 하는 코드를 짜서 해당 데이터를 histplot으로 나타낼 수 있을 것이다.
하지만 displot을 이용하면 데이터 추출 코드를 작성 할 필요없이 위와 같이 비교하여 보여준다.
이때 row, col 속성에는 범주형 데이터를 가진 feature명을 넣어주면 해당 범주로 나눠서 보여준다.
2-3 countplot
plt.figure(figsize=(12, 4))
sns.countplot(data=data, x='species', palette='Set2')
plt.figure(figsize=(12, 4))
sns.countplot(data=data, x='flipper_length_mm', palette='viridis')
plt.show()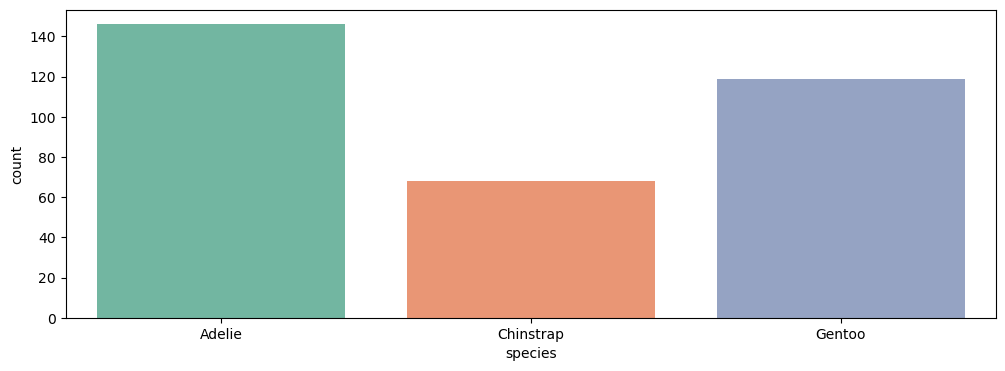
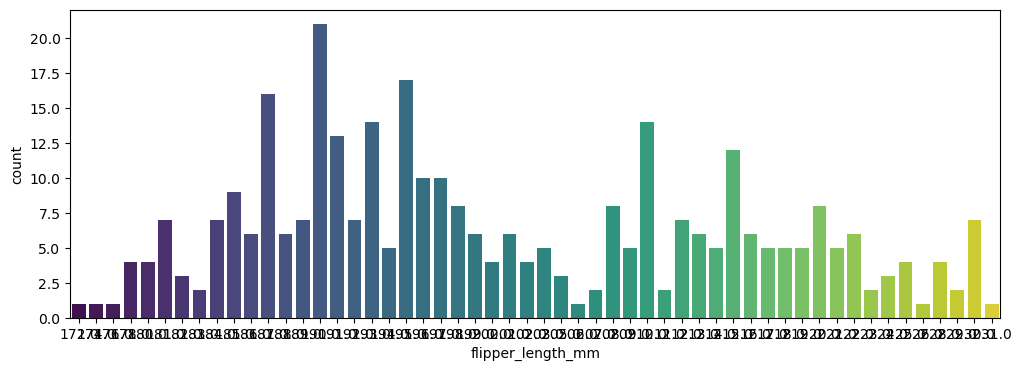
countplot은 범주에 따른 데이터 개수 파악을 위해 사용된다.
따라서 x값에는 범주형 데이터를 가지는 feature명을 입력해 줘야한다.
두 번째 그래프는 실험적으로 x값에 범주가 아닌 수치형 데이터를 가진 feature를 입력으로 주고 출력해 본 것이다.
이를 사용해서도 분포를 알 수는 있긴 하지만 이보다는 histplot을 이용하는 것이 더 적절하다.(histplot은 bins 속성을 통해 분포의 크기를 조절 가능)
2-4 barplot
plt.figure(figsize=(12, 4))
sns.barplot(data=data, x='species', y='body_mass_g', errorbar=None, hue='species', palette='Set2')
plt.figure(figsize=(12, 4))
sns.barplot(data=data, y='species', x='body_mass_g', errorbar=None, hue='species', palette='Set2')
plt.show()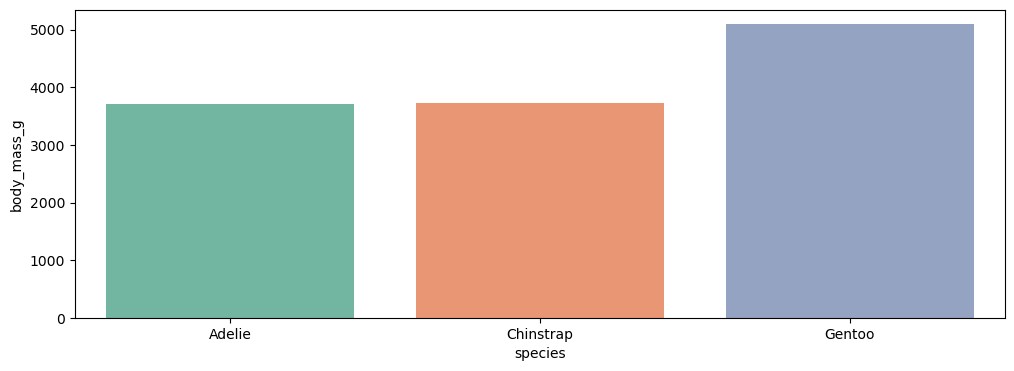
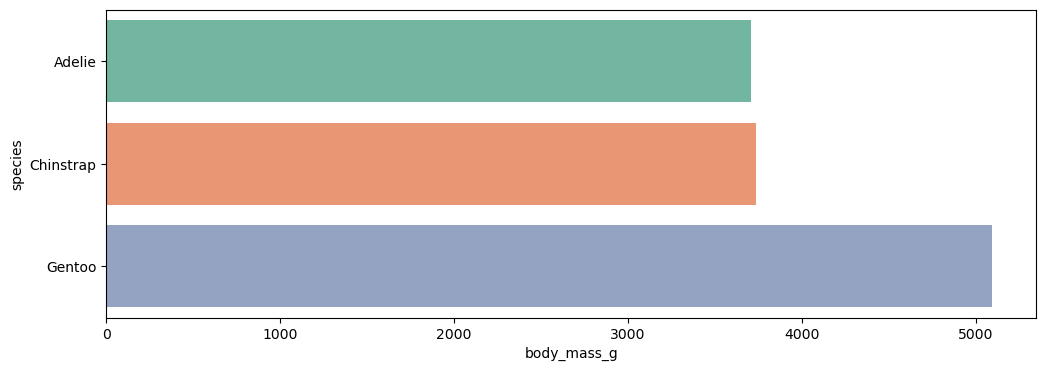
barplot은 범주(집단)마다 가지고 있는 특정 (수치형 데이터)속성의 대표값(평균)을 보고싶을 때 사용하는 그래프이다.
3. 선 그래프 : lineplot
import numpy as np
temp = data.sort_values(by='body_mass_g')
temp['time'] = np.arange(len(temp))
sns.lineplot(data=temp, x='time', y='body_mass_g')
sns.lineplot(x=data.index, y=data.body_mass_g)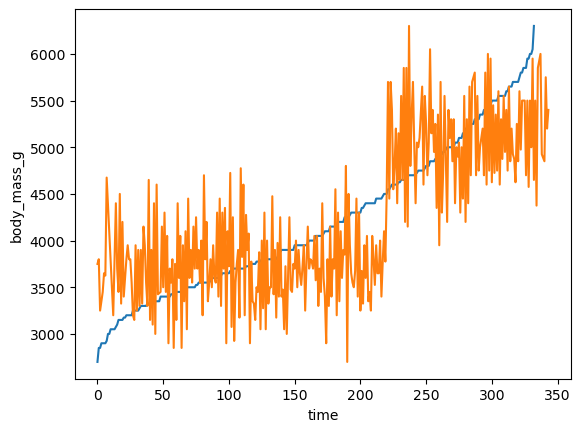
lineplot은 시간의 변화에 따른 (수치형)데이터의 변화를 보기위해 주로 사용된다.
물론 시간이 아닌 다른 특정 데이터의 연속적 변화에 따른 (수치형)데이터의 변화를 보기위해서 사용해도 된다.
x 속성으로는 주로 시간이 오지만 수치형 데이터를 가진 feature 명만 오면 가능하다.
y 속성으로는 x의 연속적 변화에 따라 보고싶은 수치형 데이터를 가진 feature 명을 입력하면 된다.
4. IQR 그래프(박스 그래프) : boxplot
sns.boxplot(data=data, x='species', y='body_mass_g', palette='Set2')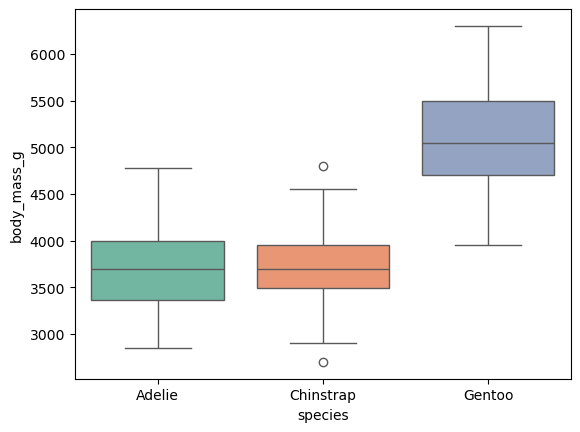
박스그래프는 주로 연속형 데이터의 분포를 한눈에 보기위해 사용한다.
따라서 x속성에는 범주형 데이터를 가지는 faeture의 이름을, y속성에는 분포를 한 눈에 보고싶은 연속형 데이터를 가지는 feature이름을 주면 된다.
5. 점 그래프 : scatterplot, pairplot
5-1 scatterplot
sns.scatterplot(data=data,
x='bill_length_mm',
y='flipper_length_mm',
hue='species')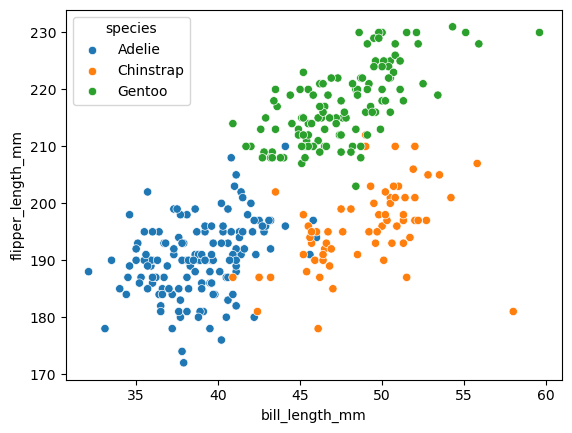
scatterplot은 데이터의 두 가지 (수치 형)feature에 따른 군집 또는 경향을 보기위해서 사용된다.
따라서 x속성과 y속성에는 수치형 데이터를 가지는 feature의 이름을 입력해 주면 된다.
5-2 pairplot
sns.pairplot(data=data, hue='species')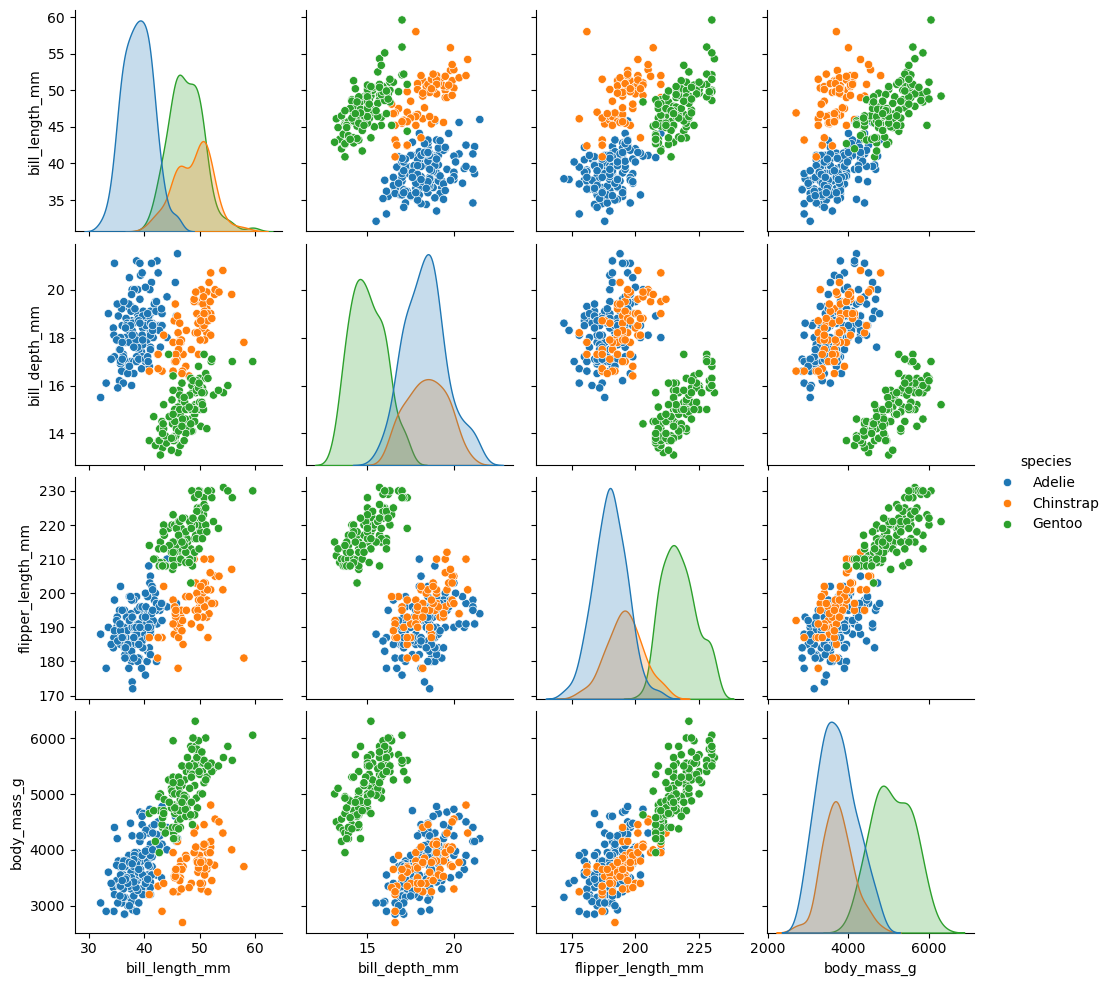
pairplot은 catterplot의 x, y 속성을 무엇을 할지 고민되고 정하기 귀찮을 때 모든 조합을 보기위해서 사용된다.
6. 히트맵: heatmap
corr = data.corr(numeric_only=True)
corr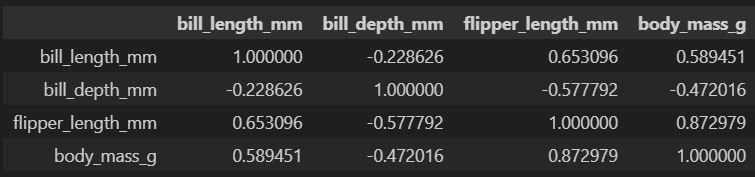
corr(numeric_only=True) 함수를 사용하면 수치형 데이터 쌍의 상관계수를 확인 할 수 있다.
상관 계수란 두 속성이 얼마나 관계가 큰지를 나타내는 것이다.
1에 가까우면 한 속성의 값이 증가하면 다른 값도 함께 증가하는 경향이 있음을 의미한다.
-1에 가까우면 반대를 의미한다.
sns.heatmap(data=corr, annot=True, fmt='.4f', cmap='Reds')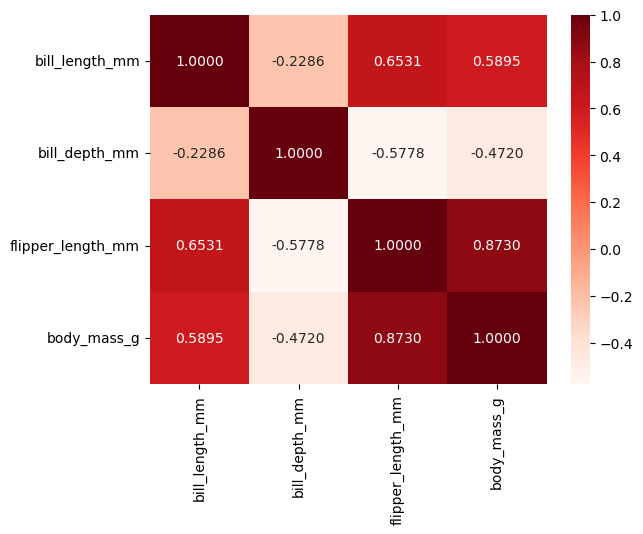
heatmap은 상관계수를 시각적으로 표현하여 두 속성의 상관성을 한눈에 보기위해 사용된다.
'EDA > seaboarn' 카테고리의 다른 글
| 데이터 시각화 연습 문제 ) 삼성전자 매출액 데이터를 시각화 해보자! (0) | 2024.05.19 |
|---|
