
데이터 한번 배워봤다면 다들 아는 그 데이터!!!
맞다 seaborn에 들어 있는 iris 데이터를 사용해서
데이터 과학자들은 붓꽃의 종류별로 꽃 받침의 너비가서로 다르다는 것을 증명하는
하찮지만 엄청 멋있게 증명하는 과정을 적어볼 것이다.
일단 데이터가 어떻게 주어지는지 부터 보자.
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
target_df = pd.DataFrame(data = iris.target, columns=['target'])
df = pd.concat([iris_df, target_df], axis=1)
df.columns = ['seapal_length', 'sepal_width', 'petal_length', 'petal_width', 'target']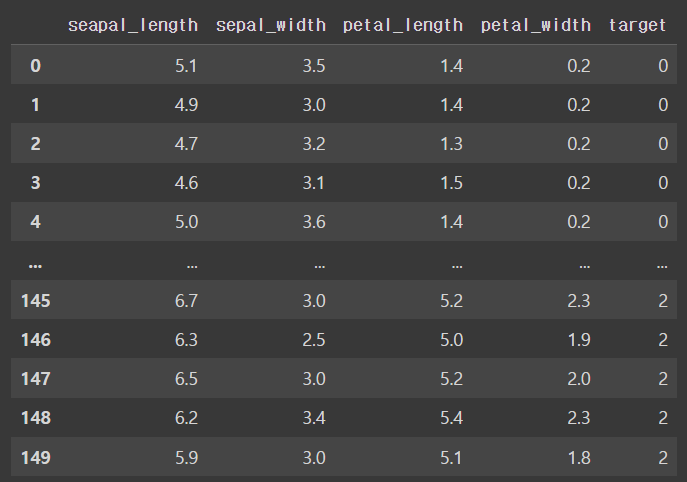
코드를 작성하면 다음과 같은 표를 얻을 수 있다.
150개의 데이터가 있고 이는 붓꽃의 꽃받침 길이, 너비 , 꽃잎의 길이, 너비 그리고 붓꽃의 종
을 나타내는 데이터 이다.
target 열이 붓꽃의 종을 뜻하는 것인데
0 이면 'setosa', 1이면 'versicolor', 2이면 'viginica' 종을 의미한다.
각 종은 50개씩 데이터가 있다.
이 데이터를 보고 각 종이 서로 다른 꽃받침 너비를 가지고 있음을 보이라고 한다.
당신은 어떻게 할 것인가?
0. 평균 구해서 비교하면 되는 것 아닌가?
쉽게 각 종별로 꽃받침 너비의 평균을 구해서 비교하면 되는 간단한 일 아닌가?
import seaborn as sns
import matplotlib.pyplot as plt
sns.boxplot(x='target', y='sepal_width', data=df)
plt.show()위 코드를 실행하면 다음 그래프를 확인 할 수 있다.
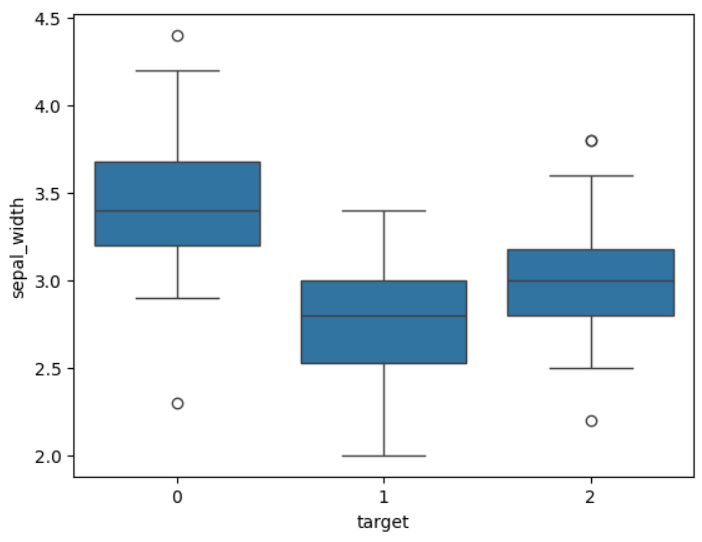
딱 봐도 3개의 종이 평균이 다르다.!!
일반인들은 여기서 분석이 끝이 나겠지만 데이터 과학자는 고민에 휩싸인다.
왜냐?
바로 50개 밖에 데이터가 되지 않기 때문이다.
즉 위 데이터가 "표본"이기 때문이다.
' 표본을 우연히 이상하게 뽑아서 평균이 서로 다르게 보이느거 아니야?'
'다른 표본 뽑으면 차이가 좁아지는거 아니야?'
즉

'표본을 어떻게 믿어!!!!'
라는 큰 문제가 있다.
그것을 멋있는 전문 용어로 표본의 "불확실성" 이라고 한다.
이를 제거하기 위해서는
다음과 같은 과정을 거쳐 데이터 과학자는 증명을 한다.
1. 정규성 검정 : 표본들이 정규분포를 따르는가?
2. 등분산성 검정 : 표본들이 같은 분산을 가지고 있는가?
3. 일원분산분석 : 집단들 중 다른 평균을 가지고 있는 집단이 있는가?
4. 사후 분석 : 있다면 누구하고 누가 다른 집단인가?
하나씩 해보자...
1. 정규성 검정
표본들이 정규분포를 따르는지 안따르는지를 판단하는 과정이다.
정규분포를 따르면 조금 쉽게 ANOVA(분산 분석)을 할 수 있지만
정규 분포를 따르지 않는 순간 "비모수 통계" 라는 안타까운 과정을 거쳐야만 한다.

기도를 하면서 정규성을 만족 하는지 않하는지 판단하는 방법을 알아보자
1. 그려보고 정규분포 모양으로 나오는가?
2. 왜도가 2 이하 첨도가 7이하 인가?
3. 정규성 검정 (샤피로-월크 등)
참고로 정규성 검정을 만족하면 다른 것은 볼 필요도 없다.
왜냐하면 엄청나게 엄격하기 때문이다.
무려 정규분포를 따른다 할지라도 조금이라도 샘플이 잘 못되면 기각해버린다.
아름답지 않은 노이즈가 그득그득 끼어있는 실제 데이터에서는 정규성 검정으로 정규성을 만족함을 보이기는 매우 어렵다고 한다.
따라서 보통은 그려보거나 왜도나 첨도를 보고 판단한다고 한다.
우리는 공부하는 입장에서 3가지 모두 다 해보자.
# 1. 그래프 그리자
plt.figure()
plt.hist(df.sepal_width[df.target == 0], alpha=0.5, bins=20)
plt.figure()
plt.hist(df.sepal_width[df.target == 1], alpha=0.5, bins=20)
plt.figure()
plt.hist(df.sepal_width[df.target == 2], alpha=0.5, bins=20)
plt.show()
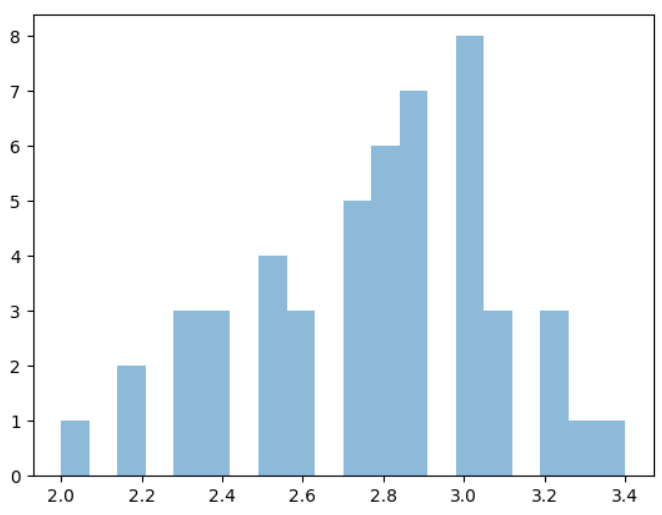
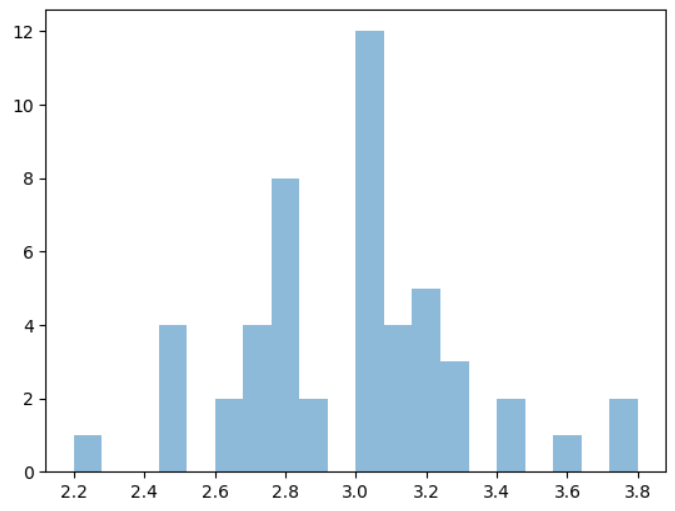
나름 정규 분포가 보이....나..?

그래서 두 번째 방법!!!
"왜도가 2이하 첨도가 7이하면 정규분포를 따른다" 로 증명을 해보자.
# 2 왜도 첨도 값을 구하자 => 왜도는 2 첨도는 7 이하면 정규성 만족으로 판단
import scipy.stats as stats
print("왜도 : ", stats.skew(df.sepal_width[df.target == 0]), '\t첨도 : ', stats.kurtosis(df.sepal_width[df.target == 0]))
print("왜도 : ",stats.skew(df.sepal_width[df.target == 1]), '\t첨도 : ', stats.kurtosis(df.sepal_width[df.target == 1]))
print("왜도 : ",stats.skew(df.sepal_width[df.target == 2]), '\t첨도 : ', stats.kurtosis(df.sepal_width[df.target == 2]))
다행히 2이하 7이하를 만족한다.
즉 정규성을 증명 하였다!!!

그래도 마지막 방법인 정규성 검정으로도 해결해보자.
정규성 검정은 가설을 두고 확률적으로 판단하는 것이다.
H0 : 표본은 정규분포를 따른다.
H1 : 표본은 정규분포를 따르지 않는다.
라고 해서 pvalue가 0.05보다 크면 H0 채택, 작으면 H1채택 하는 것이다.
# 정규성 검정 => 매우 엄격함 : pvalue 가 0.05보다 크면 정규성 만족
from scipy.stats import shapiro
print(shapiro(df.sepal_width[df.target == 0]))
print(shapiro(df.sepal_width[df.target == 1]))
print(shapiro(df.sepal_width[df.target == 2]))
결과를 보면 pvalue가 다 0.05보다 크다.
즉 H0을 채택한다.
2. 등분산 검정
이제 각 표본이 분산이 같은지 다른지 알아보자.
같으면 편안 하게 일반적인 t-test를 할 수 있다.

하지만 !!! 다르다고 나오는 날에는 Welch's t-test를 진행해야 한다...

가설은 다음과 같이 세운다.
H0 : 집단간에 분산이 동일 하다.
H1 : 집단 간에 분산이 동일 하지 않다(=다르다)
그러고 pvalue값을 구해서 pvalue 값이 0.05보다 작으면 다른거고 0.05보다 크면 동일한 것이다.
from scipy.stats import levene
print(levene(df.sepal_width[df.target == 0], df.sepal_width[df.target == 1], df.sepal_width[df.target == 2]))

다행해 pvalue 값이 0.555 로 0.05보다 월등히 높다.
따라서 각 표본이 같은 분산을 가지고 있음을 증명된 것이다.
3. ANOVA(일원 분산 분석)
분산 분석의 종류는 일원 분산 분석, 이원 분산 분석, 다원 분산 분석, 다변량 분산 분석 이 있다.
이번에는 쉽게 꽃 받침의 길이만을 보기때문에 일원 분산 분석을 사용하면 된다.
분산 분석을 하는 이유는 3개 이상의 집단에서 집단 중 동떨어진 평균을 가지고 있는지 파악하기 위해서 이다.
만약 여기서 그러한 집단이 없다고 증명된다면 우리의 실험은
"세 종 붓꽃의 꽃받침 너비는 서로 같다" 라고 말할 수 있는 것이다.
검정을 하기전 가설을 세우자!
H0 : 집단 간 꽃받침 너비의 평균의 차이는 없다.
H1 : 집단 간 꽃받침 너비의 평균의 차이가 있다.
이를 일원 분산 분석하는 코드는 다음과 같다.
stats.f_oneway(df.sepal_width[df.target==0], df.sepal_width[df.target==1], df.sepal_width[df.target==2])
pvalue가 4.4 가 나왔다!!!!
그러나----
뒤에 잘 보면 e-17이란 수가 있다.
이는 0.000000000000000001을 뜻하는 것이다....
따라서 실제 pvalue는 0.00000000000000004492... 이다.
즉 H0 기각 H1 채택...
"집단 간 꽃받침 너비의 평균의 차이가 있다" 라는 의미이다...
하지만 여기서는 어떤 집단과 어떤 집단이 평균의 차이가 있는지 알 수 없다.
따라서 사후분석이 필요하다.
4. 사후분석
정확히 어떤 집단과 어떤 집단이 평균의 차이가 있는지 파악하기 위해 하는 작업이다.
코드는 다음과 같다.
from statsmodels.stats.multicomp import pairwise_tukeyhsd
hsd = pairwise_tukeyhsd(df.sepal_width, df.target, alpha = 0.05)
hsd.summary()
p-adj를 보면 다들 0.05보다 훨씬 작은것이 눈에 들어온다.
또한 우리 편하라고 reject에 정확히 True라고 적혀 있다.
한 줄 씩보면
첫번째 줄은 0번 집단과 1번 집단의 평균이 다른지 분석한 것이고 결과는 "서로다르다"
두번째 줄은 0번 집단과 2번집단의 평균이 다른지 분석한 것이고 결과는 "서로다르다"
세번째 줄은 1번 집단과 2번집단의 평균이 다른지 분석한 것이고 결과는 "서로다르다"
즉 모든 집단의 평균은 다르다 를 의미한다.
이렇게 데이터 과학자는 눈으로 보면 딱봐도 다르다는 것을 증명하기 위한 과정이 끝이 난다...
중간중간에 보면 많은 개념들이나오고 또 그저 코드로 계산을 다 맡겼지만 왜 그러한 값이 나오고 어떻게 계산되는지 수식의 의미는 뭔지는 다 빼고 보았다.
데이터 과학자가 되기 위해서는 각 과정에 사용되는 수식을 분석하고 파악해야한다...
화이팅...